black==23.3.0
fastparquet==2023.4.0
hyperopt==0.2.7
mlflow==2.3.1
pandas==2.0.1
prefect==2.10.8
prefect-aws==0.3.1
scikit_learn==1.2.2
seaborn==0.12.2
xgboost==1.7.5
orjson==3.8.13.1 Introduction to Workflow Orchestration
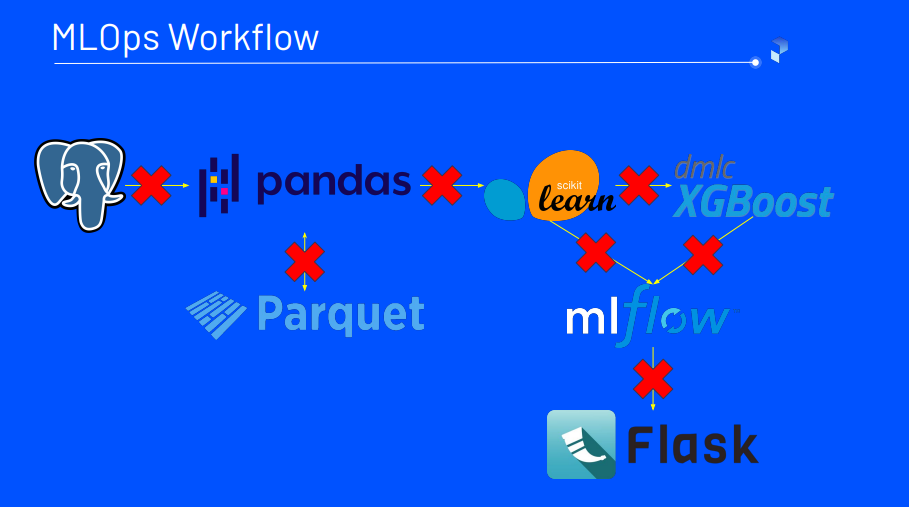
Orchestrating an ML workflow can be quite challenging. There are a lot of potential breakpoints in the flow, as indicated by the red crosses in the example typical flow below :
Thankfully there are tools avaialable to help with this. Prefect provides a modern, robust, and user-friendly approach to workflow orchestration, simplifying the management of complex data pipelines and enabling efficient and reliable execution. monitoring and visualization of your workflows.
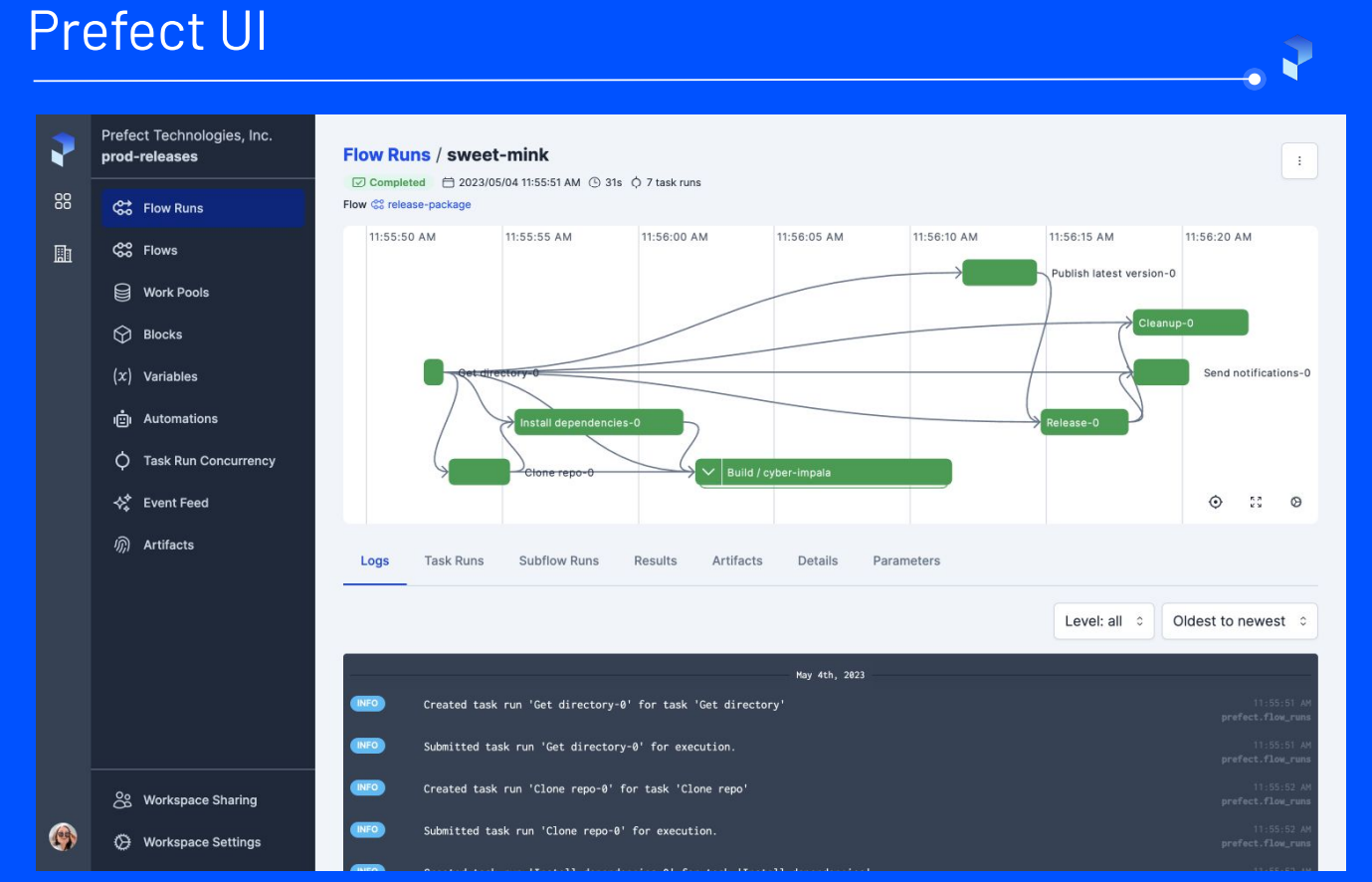
A screenshot of the Prefect UI illustrating how a typical flow might be orchestrated is included below :
3.2 Introduction to Prefect

3.2.1 Why use Prefect?

Ease of Use:
Prefect provides a user-friendly interface and a Python-based API, making it easy to define and manage workflows. It allows you to write workflows as code, leveraging your existing Python knowledge and infrastructure.
Flexibility:
Prefect offers a flexible and extensible framework for defining workflows. It supports complex dependencies and allows you to handle dynamic data-driven workflows. You can easily create, update, and version your workflows as your needs evolve.
Fault Tolerance:
Prefect provides built-in fault tolerance and retry mechanisms. It handles failures gracefully by automatically retrying failed tasks and recovering from errors. You can configure custom error handling and notifications to ensure that your workflows run reliably.
Monitoring and Observability:
Prefect offers comprehensive monitoring and observability features. It provides a web-based dashboard where you can visualize and track the status of your workflows, inspect task-level details, and monitor execution metrics. This allows for easy debugging, performance optimization, and troubleshooting.
Scalability:
Prefect is designed to scale horizontally, allowing you to execute workflows on a distributed infrastructure. It supports parallel and distributed execution, enabling you to run tasks concurrently across multiple machines or containers. This makes it suitable for handling large-scale data processing and complex workflows.
Integration and Extensibility:
Prefect integrates seamlessly with various technologies and services, such as databases, message queues, cloud platforms, and more. It provides a rich set of task libraries and allows you to extend its functionality through custom task definitions and hooks. This enables you to integrate Prefect into your existing tech stack and leverage the power of your ecosystem.
Workflow Visibility and Collaboration:
Prefect promotes collaboration and visibility among teams. It offers features like version control, sharing, and collaborative editing of workflows. You can easily share and reuse workflows across projects, enabling better collaboration and knowledge sharing within your organization.



In the above example we have a parent flow named Hellow Flow which calls on the the subflow Subflow.
3.2.2 Clone Prefect GitHub repo
To clone the Prefect repo navigate to the directory where you want to clone to and from the command line :
git clone git@github.com:discdiver/prefect-mlops-zoomcamp.git
Note I am using the SSH method for cloning. You can also use the HTTPS or CLI methods if you prefer.
3.2.3 Set up a Conda environment
Now, from within our cloned repo, let’s create a conda environment using the following :
conda create -n prefect-ops python==3.9.12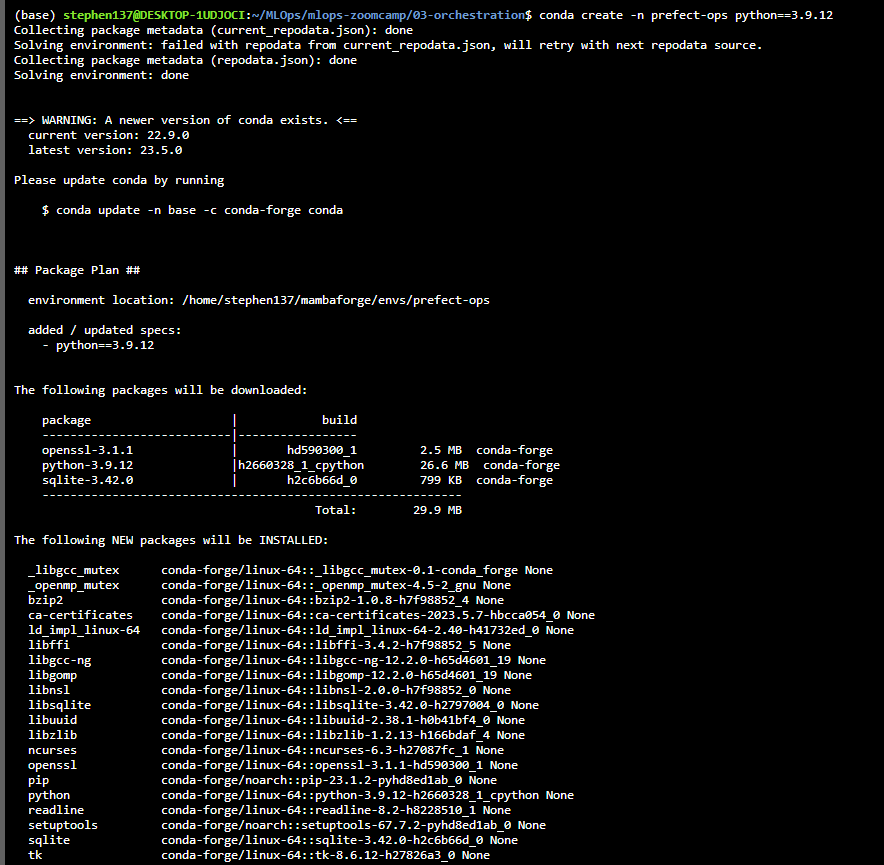
and activate the environment using :
conda activate prefect-ops Quickly check we are using the correct Python version :
python -VThen pip install the dependencies included in the requirements.txt file :
pip install -r requirements.txtrequirements.txt
3.2.4 Start a Prefect Server
We can start a Prefect server from the command line :
prefect server start
Let’s grab the API URL and make sure that we apply this to our Prefect configuration so that we are pointing to the correct API URL.
Within a new terminal, navigate to the same directory as before, activate the conda environment and set the API URL:
prefect config set PREFECT_API_URL=http://127.0.0.1:4200/api
OK, let’s now navigate to the 3.2 folder where the scripts we will be using for illustration purposes live :
cat_facts.py
import httpx
from prefect import flow, task
@task(retries=4, retry_delay_seconds=0.1, log_prints=True) # decorator
def fetch_cat_fact():
cat_fact = httpx.get("https://f3-vyx5c2hfpq-ue.a.run.app/")
#An endpoint that is designed to fail sporadically
if cat_fact.status_code >= 400:
raise Exception()
print(cat_fact.text) # this will be logged
@flow
def fetch():
fetch_cat_fact()
if __name__ == "__main__":
fetch()The function calling the API has been decorated with a task decorator which has been configured with the arguments retries, retry_delay_seconds, and log_prints.
We can run the flow from the command line using :
python cat_facts.py
and follow the run live from the Prefect UPI :
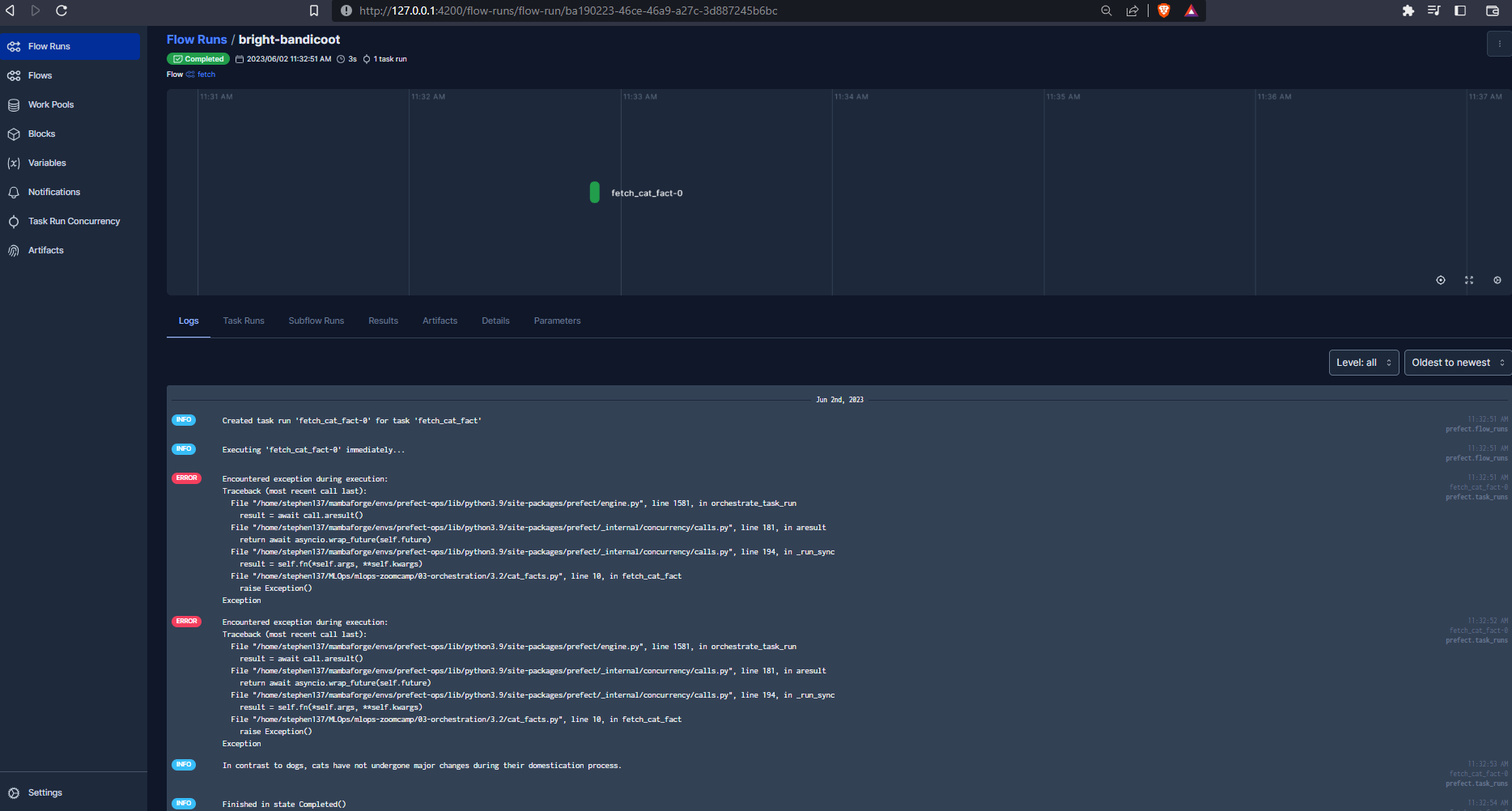
As we can see, the flow failed a couple of times, but the retries argument included within the decorator kicked in. And we have our cat fact logged :
“In contrast to dogs, cats have not undergone major changes during their domestication process.”
Let’s now run the other script :
python cat_dog_facts.pycat_dog_facts.py
import httpx
from prefect import flow
@flow
def fetch_cat_fact():
'''A flow that gets a cat fact'''
return httpx.get("https://catfact.ninja/fact?max_length=140").json()["fact"]
@flow
def fetch_dog_fact():
'''A flow that gets a dog fact'''
return httpx.get(
"https://dogapi.dog/api/v2/facts",
headers={"accept": "application/json"},
).json()["data"][0]["attributes"]["body"] # index into the JSON file to retrieve the "body" - see below for example of JSON format
@flow(log_prints=True)
def animal_facts():
cat_fact = fetch_cat_fact()
dog_fact = fetch_dog_fact()
print(f"🐱: {cat_fact} \n🐶: {dog_fact}")
if __name__ == "__main__":
animal_facts(){“data”:[{“id”:“96f49d0c-64d1-43f4-87e1-6f7e8796d89d”,“type”:“fact”,“attributes”:{“body”:“There are 703 breeds of purebred dogs.”}}]}
This script utilises Subflows. The parent flow animal_facts calls fetch_cat_fact and then fetch_dog_fact. Note that beacuse log_prints=True the output of the flows is printed and logged.
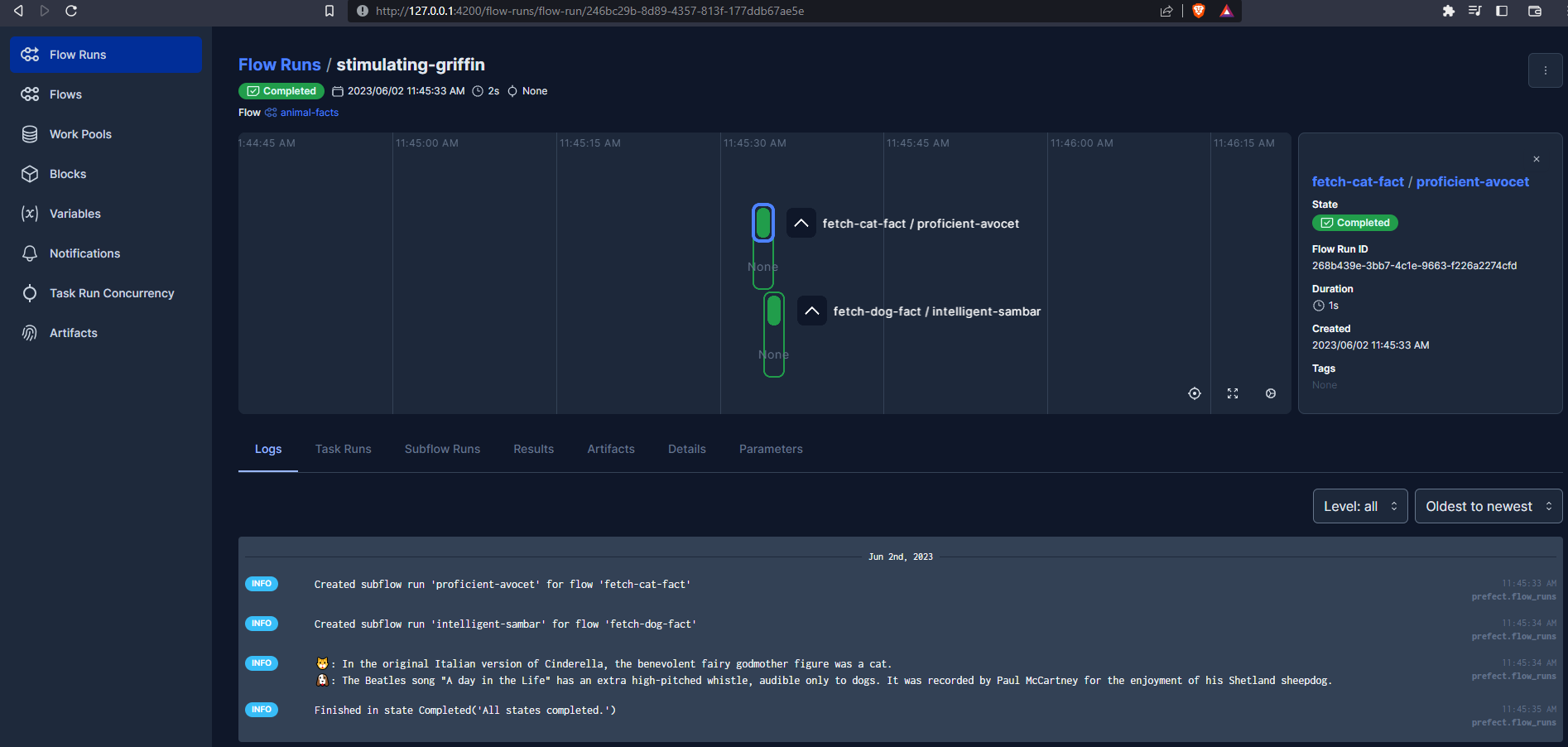
🐱: In the original Italian version of Cinderella, the benevolent fairy godmother figure was a cat.
🐶: The Beatles song “A day in the Life” has an extra high-pitched whistle, audible only to dogs. It was recorded by Paul McCartney for the enjoyment of his Shetland sheepdog.
3.3 Prefect Workflow
3.3.1 Improving the duration prediction NoteBook from Module 2
In Module 2 Alexey walked us through one possible approach to build a simple taxi trip duration prediction model. The code was deliberately compiled in a somewhat flow of consciousness Jupyter NoteBook to illustrate :
- the thought process and general steps involved in exploring and pre-processing raw data for machine learning training
- that whilst a Jupyter Notebook is fine for internal experimentation, when it comes to production/deployment perhaps we need something more robust/scalable
When code is scattered throughout a Jupyer NoteBook, things can quickly start to get messy, especially when you start iterating over different models and parameters. There can be a sense that you are losing control over your experiment. A first step towards improvement is to bring everything together into a single Python script.
3.3.2 Duration prediction NoteBook pulled together into a Python script
A first step towards improvement is to bring everything together into a single Python script :
orchestrate_pre_prefect.py
import pathlib
import pickle
import pandas as pd
import numpy as np
import scipy
import sklearn
from sklearn.feature_extraction import DictVectorizer
from sklearn.metrics import mean_squared_error
import mlflow
import xgboost as xgb
from prefect import flow, task
def read_data(filename: str) -> pd.DataFrame:
"""Read data into DataFrame"""
df = pd.read_parquet(filename)
df.tpep_dropoff_datetime = pd.to_datetime(df.tpep_dropoff_datetime)
df.tpep_pickup_datetime = pd.to_datetime(df.tpep_pickup_datetime)
df["duration"] = df.tpep_dropoff_datetime - df.tpep_pickup_datetime
df.duration = df.duration.apply(lambda td: td.total_seconds() / 60)
df = df[(df.duration >= 1) & (df.duration <= 60)]
categorical = ["PULocationID", "DOLocationID"]
df[categorical] = df[categorical].astype(str)
return df
def add_features(
df_train: pd.DataFrame, df_val: pd.DataFrame
) -> tuple(
[
scipy.sparse._csr.csr_matrix,
scipy.sparse._csr.csr_matrix,
np.ndarray,
np.ndarray,
sklearn.feature_extraction.DictVectorizer,
]
):
"""Add features to the model"""
df_train["PU_DO"] = df_train["PULocationID"] + "_" + df_train["DOLocationID"]
df_val["PU_DO"] = df_val["PULocationID"] + "_" + df_val["DOLocationID"]
categorical = ["PU_DO"] #'PULocationID', 'DOLocationID']
numerical = ["trip_distance"]
dv = DictVectorizer()
train_dicts = df_train[categorical + numerical].to_dict(orient="records")
X_train = dv.fit_transform(train_dicts)
val_dicts = df_val[categorical + numerical].to_dict(orient="records")
X_val = dv.transform(val_dicts)
y_train = df_train["duration"].values
y_val = df_val["duration"].values
return X_train, X_val, y_train, y_val, dv
def train_best_model(
X_train: scipy.sparse._csr.csr_matrix,
X_val: scipy.sparse._csr.csr_matrix,
y_train: np.ndarray,
y_val: np.ndarray,
dv: sklearn.feature_extraction.DictVectorizer,
) -> None:
"""train a model with best hyperparams and write everything out"""
with mlflow.start_run():
train = xgb.DMatrix(X_train, label=y_train)
valid = xgb.DMatrix(X_val, label=y_val)
best_params = {
'learning_rate': 0.4434065752589766,
'max_depth': 81,
'min_child_weight': 10.423237853746643,
'objective': 'reg:linear',
'reg_alpha': 0.2630756846813668,
'reg_lambda': 0.1220536223877784,
'seed': 42
}
mlflow.log_params(best_params)
booster = xgb.train(
params=best_params,
dtrain=train,
num_boost_round=3,
evals=[(valid, "validation")],
early_stopping_rounds=3,
)
y_pred = booster.predict(valid)
rmse = mean_squared_error(y_val, y_pred, squared=False)
mlflow.log_metric("rmse", rmse)
pathlib.Path("models").mkdir(exist_ok=True)
with open("models/preprocessor.b", "wb") as f_out:
pickle.dump(dv, f_out)
mlflow.log_artifact("models/preprocessor.b", artifact_path="preprocessor")
mlflow.xgboost.log_model(booster, artifact_path="models_mlflow")
return None
def main_flow(
train_path: str = "./data/yellow_tripdata_2022-01.parquet",
val_path: str = "./data/yellow_tripdata_2022-02.parquet",
) -> None:
"""The main training pipeline"""
# MLflow settings
mlflow.set_tracking_uri("sqlite:///mlflow.db")
mlflow.set_experiment("nyc-taxi-experiment")
# Load
df_train = read_data(train_path)
df_val = read_data(val_path)
# Transform
X_train, X_val, y_train, y_val, dv = add_features(df_train, df_val)
# Train
train_best_model(X_train, X_val, y_train, y_val, dv)
if __name__ == "__main__":
main_flow()First navigate to the directory where orchestrate_pre_prefect.py lives and run from the command line :
python orchestrate_pre_prefect.py
Further refinement can be added using Prefect. Let’s take a look at this in action.
3.3.2 Leveraging Prefect to improve the script further through orchestration
We can build further on the Python script by adding task and flow decorators :
orchestrate.py
import pathlib
import pickle
import pandas as pd
import numpy as np
import scipy
import sklearn
from sklearn.feature_extraction import DictVectorizer
from sklearn.metrics import mean_squared_error
import mlflow
import xgboost as xgb
from prefect import flow, task
@task(retries=3, retry_delay_seconds=2)
def read_data(filename: str) -> pd.DataFrame:
"""Read data into DataFrame"""
df = pd.read_parquet(filename)
df.tpep_dropoff_datetime = pd.to_datetime(df.tpep_dropoff_datetime)
df.tpep_pickup_datetime = pd.to_datetime(df.tpep_pickup_datetime)
df["duration"] = df.tpep_dropoff_datetime - df.tpep_pickup_datetime
df.duration = df.duration.apply(lambda td: td.total_seconds() / 60)
df = df[(df.duration >= 1) & (df.duration <= 60)]
categorical = ["PULocationID", "DOLocationID"]
df[categorical] = df[categorical].astype(str)
return df
@task
def add_features(
df_train: pd.DataFrame, df_val: pd.DataFrame
) -> tuple(
[
scipy.sparse._csr.csr_matrix,
scipy.sparse._csr.csr_matrix,
np.ndarray,
np.ndarray,
sklearn.feature_extraction.DictVectorizer,
]
):
"""Add features to the model"""
df_train["PU_DO"] = df_train["PULocationID"] + "_" + df_train["DOLocationID"]
df_val["PU_DO"] = df_val["PULocationID"] + "_" + df_val["DOLocationID"]
categorical = ["PU_DO"] #'PULocationID', 'DOLocationID']
numerical = ["trip_distance"]
dv = DictVectorizer()
train_dicts = df_train[categorical + numerical].to_dict(orient="records")
X_train = dv.fit_transform(train_dicts)
val_dicts = df_val[categorical + numerical].to_dict(orient="records")
X_val = dv.transform(val_dicts)
y_train = df_train["duration"].values
y_val = df_val["duration"].values
return X_train, X_val, y_train, y_val, dv
@task(log_prints=True)
def train_best_model(
X_train: scipy.sparse._csr.csr_matrix,
X_val: scipy.sparse._csr.csr_matrix,
y_train: np.ndarray,
y_val: np.ndarray,
dv: sklearn.feature_extraction.DictVectorizer,
) -> None:
"""train a model with best hyperparams and write everything out"""
with mlflow.start_run():
train = xgb.DMatrix(X_train, label=y_train)
valid = xgb.DMatrix(X_val, label=y_val)
best_params = {
'learning_rate': 0.4434065752589766,
'max_depth': 81,
'min_child_weight': 10.423237853746643,
'objective': 'reg:linear',
'reg_alpha': 0.2630756846813668,
'reg_lambda': 0.1220536223877784,
'seed': 42
}
mlflow.log_params(best_params)
booster = xgb.train(
params=best_params,
dtrain=train,
num_boost_round=3,
evals=[(valid, "validation")],
early_stopping_rounds=3,
)
y_pred = booster.predict(valid)
rmse = mean_squared_error(y_val, y_pred, squared=False)
mlflow.log_metric("rmse", rmse)
pathlib.Path("models").mkdir(exist_ok=True)
with open("models/preprocessor.b", "wb") as f_out:
pickle.dump(dv, f_out)
mlflow.log_artifact("models/preprocessor.b", artifact_path="preprocessor")
mlflow.xgboost.log_model(booster, artifact_path="models_mlflow")
return None
@flow
def main_flow(
train_path: str = "./data/yellow_tripdata_2022-01.parquet",
val_path: str = "./data/yellow_tripdata_2022-02.parquet",
) -> None:
"""The main training pipeline"""
# MLflow settings
mlflow.set_tracking_uri("sqlite:///mlflow.db")
mlflow.set_experiment("nyc-taxi-experiment")
# Load
df_train = read_data(train_path)
df_val = read_data(val_path)
# Transform
X_train, X_val, y_train, y_val, dv = add_features(df_train, df_val)
# Train
train_best_model(X_train, X_val, y_train, y_val, dv)
if __name__ == "__main__":
main_flow()First navigate to the directory where orchestrate.py lives and run from the command line :
python orchestrate.py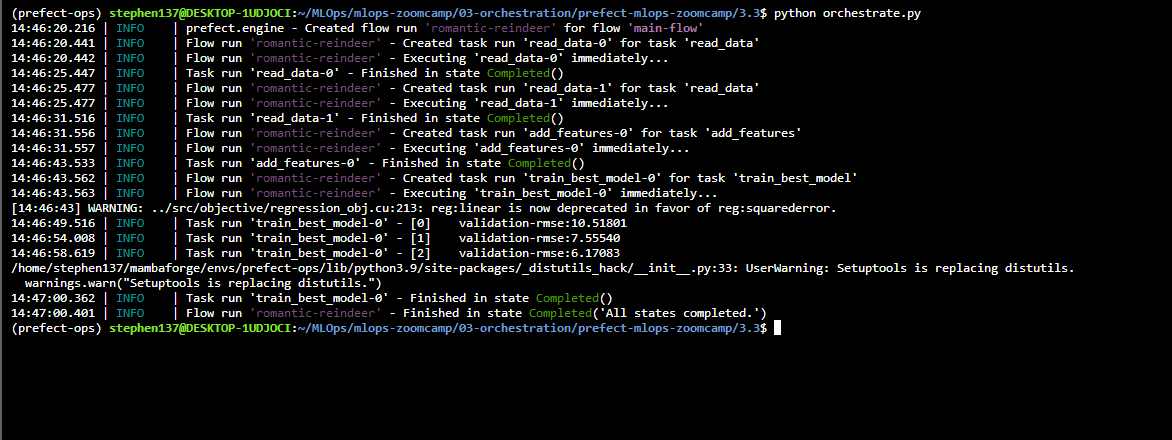
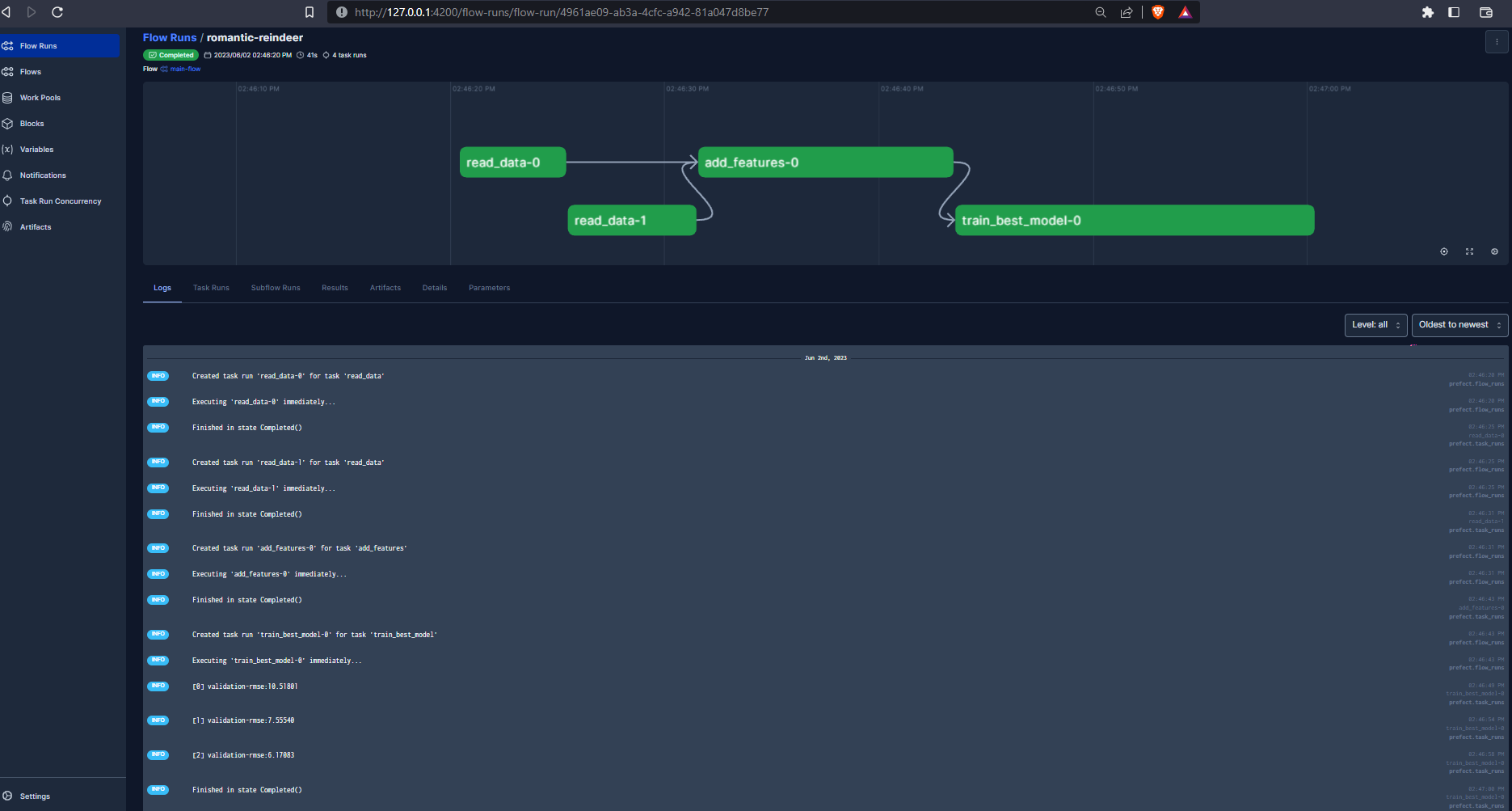
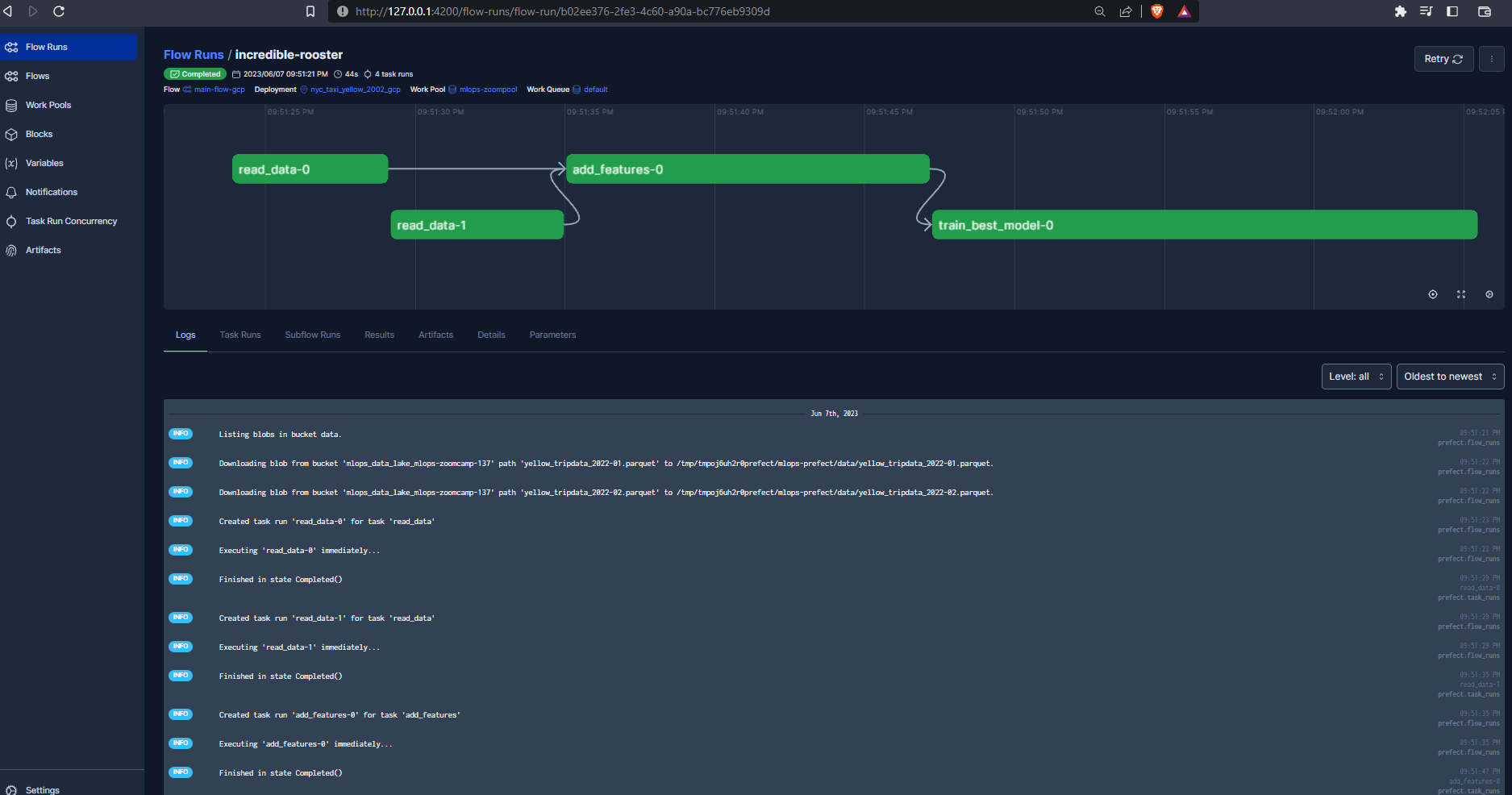
And we can visualize the run using the Prefect UI :
3.4 Deploying your Workflow
In the last section we saw how we could take a Notebook, turn it into a script, and add some Prefect task and flow decorators to make it more resilient and observable. Let’s now take the next step in productionizing our workflows and make a deployment that will live on a server, and allow us to do scheduling.
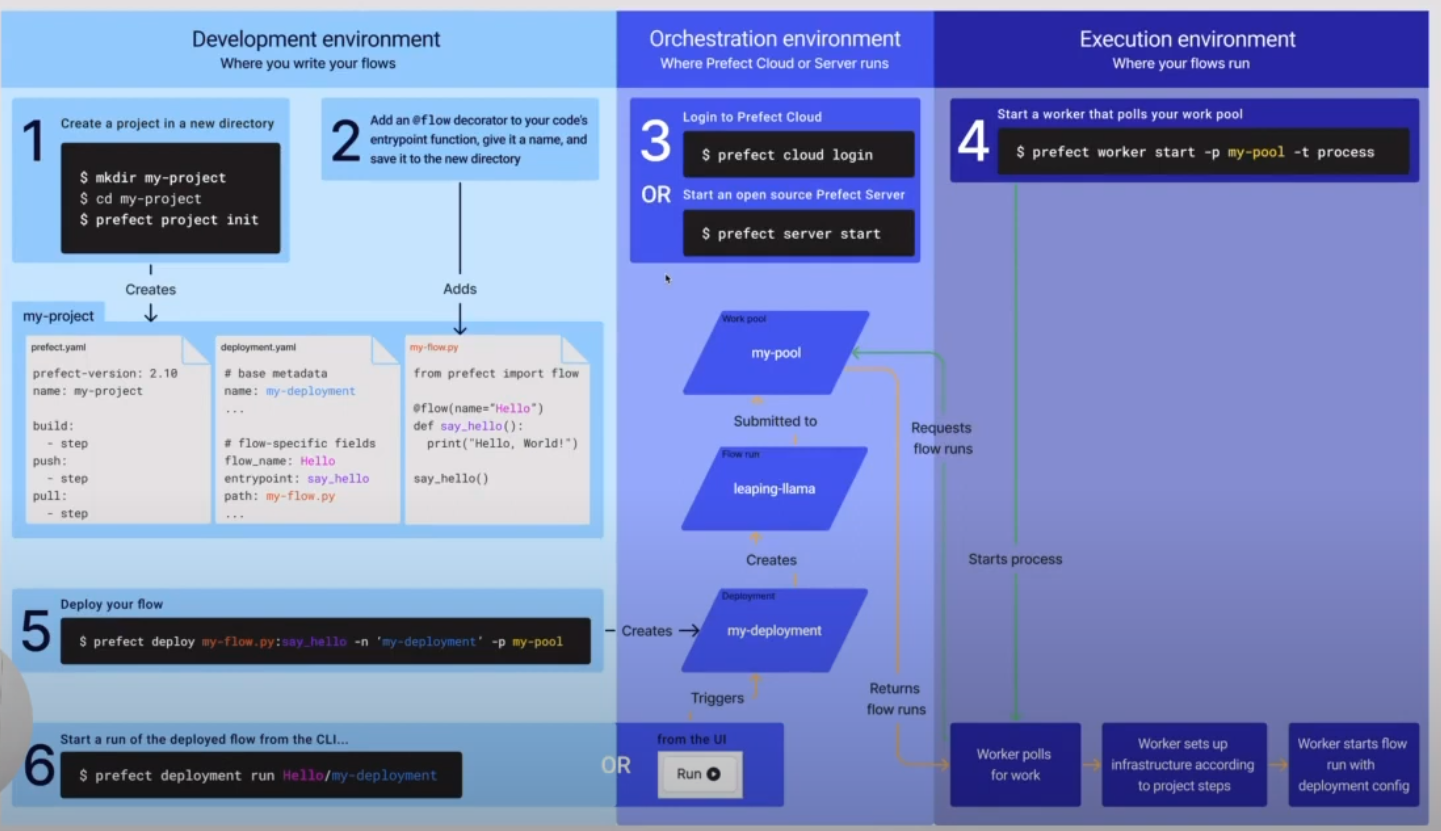
3.4.1 Create a new repo on GitHub
To use the deployment feature you need to work with a GitHub repo. First, create a new repository :
Then clone that repository to your local machine :
git clone git@github.com:Stephen137/mlops-prefect.git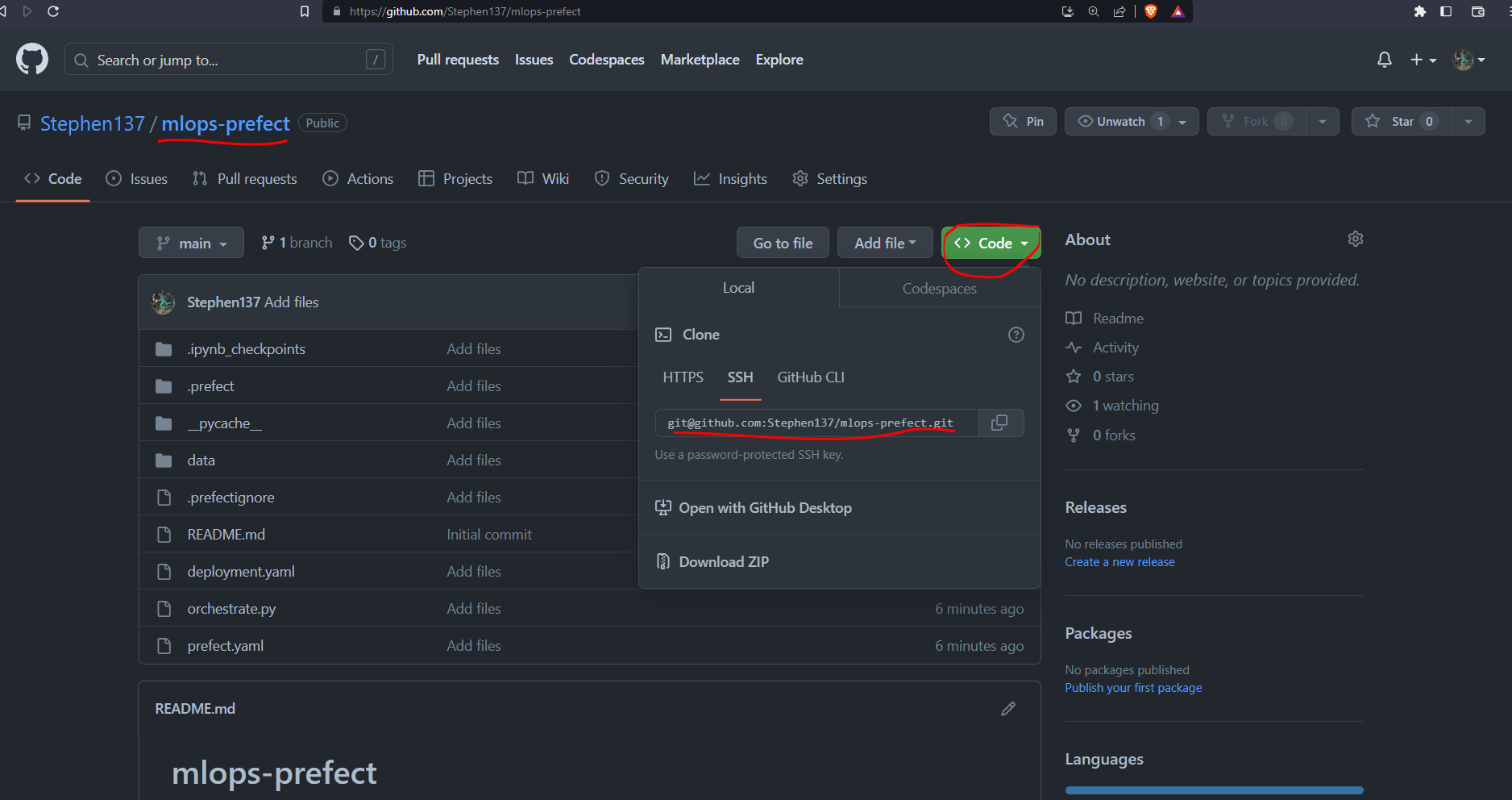
Note that I am using the password protected SSH key method to do this. The alternative is to use HTTPS :
git clone https://github.com/Stephen137/mlops-prefect.gitLet’s make a deployment using a Prefect project. Navigate to the cloned repo on your local machine and run this from the command line :
prefect project initThis creates four things :
.prefectignore - we won’t be pushing any code up automatically from Prefect
deployment.yaml - useful for templating, making multiple deployments from one project
prefect.yaml -
.prefect/ - hidden folder
Note, that all associated code and files need to present within the newly created GitHub repo, so once you have initiated the project ensure you add the above files.
Let’s now create a Work Pool from the Prefect UI :
prefect server start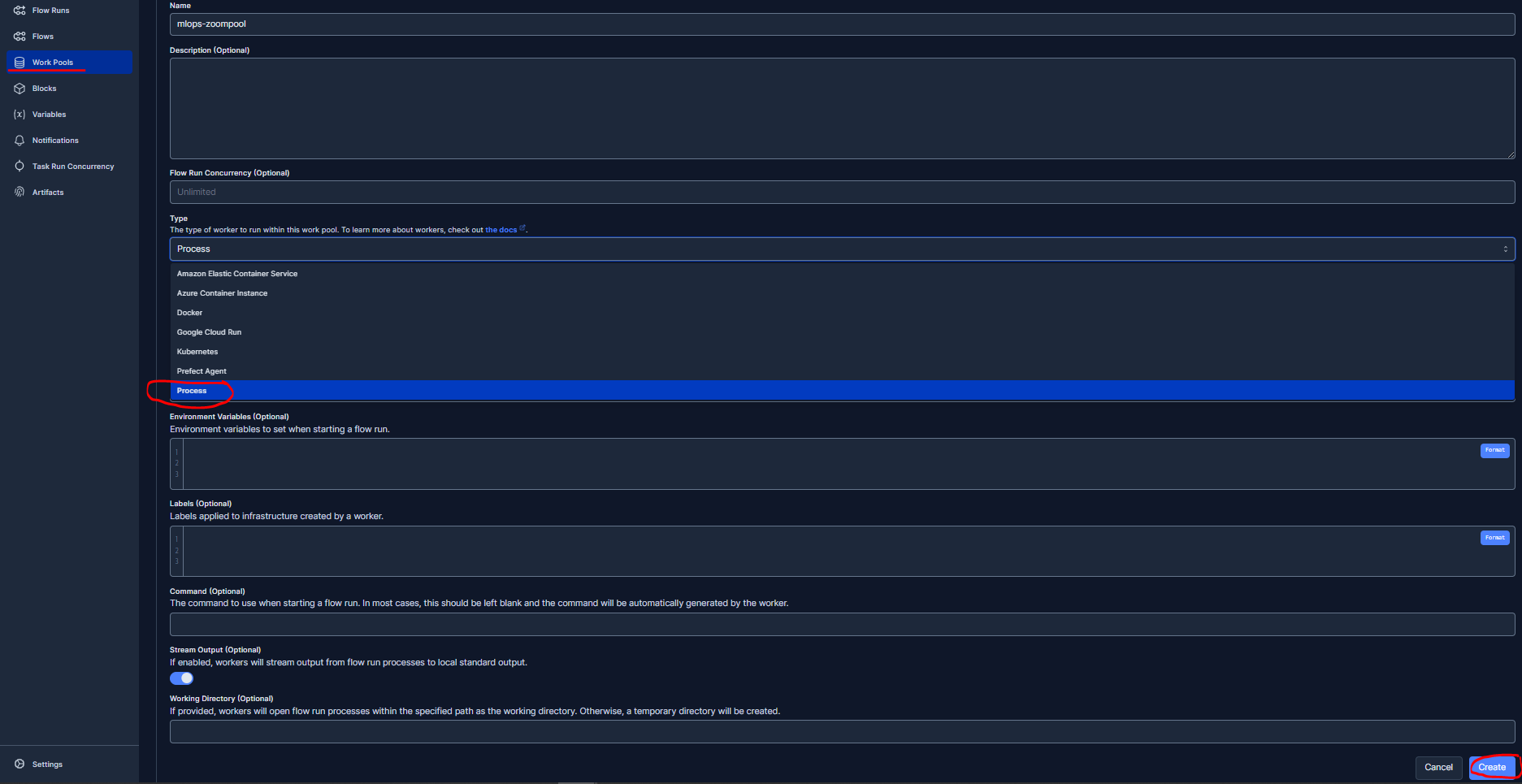
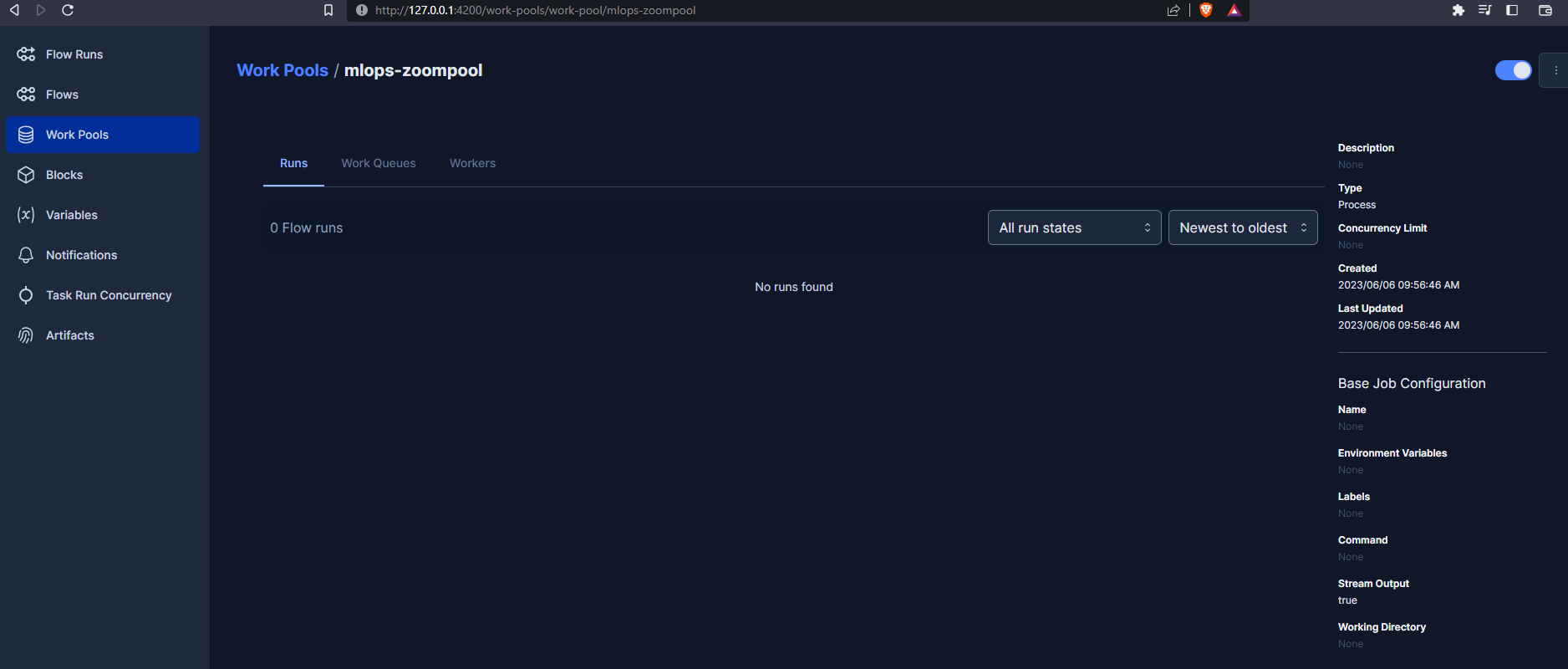
If you need help with Prefect config you can refer to the documentation or use the command :
prefect deploy --helpBefore we start a worker to poll from that pool, let’s go ahead and deploy our flow. The general template is as follows :
prefect deploy <folder_name>/<file_name>:<flow_name> -n <deploy_name> -p <work_pool_name>In my specific case here :
prefect deploy orchestrate.py:main_flow -n nyc_taxi_yellow_2022 -p mlops-zoompoolThis will send the deployment up to the server :

As we can see our deployment has been successfully created, and we are now prompted to start a worker from the mlops-zoompool. We can do this using the following template :
prefect worker start -p <work_pool_name> -t <type>In my particular case :
prefect worker start -p mlops-zoompool -t process
Finally, the last step is to start a run of the deployment. We can do this from the UI :
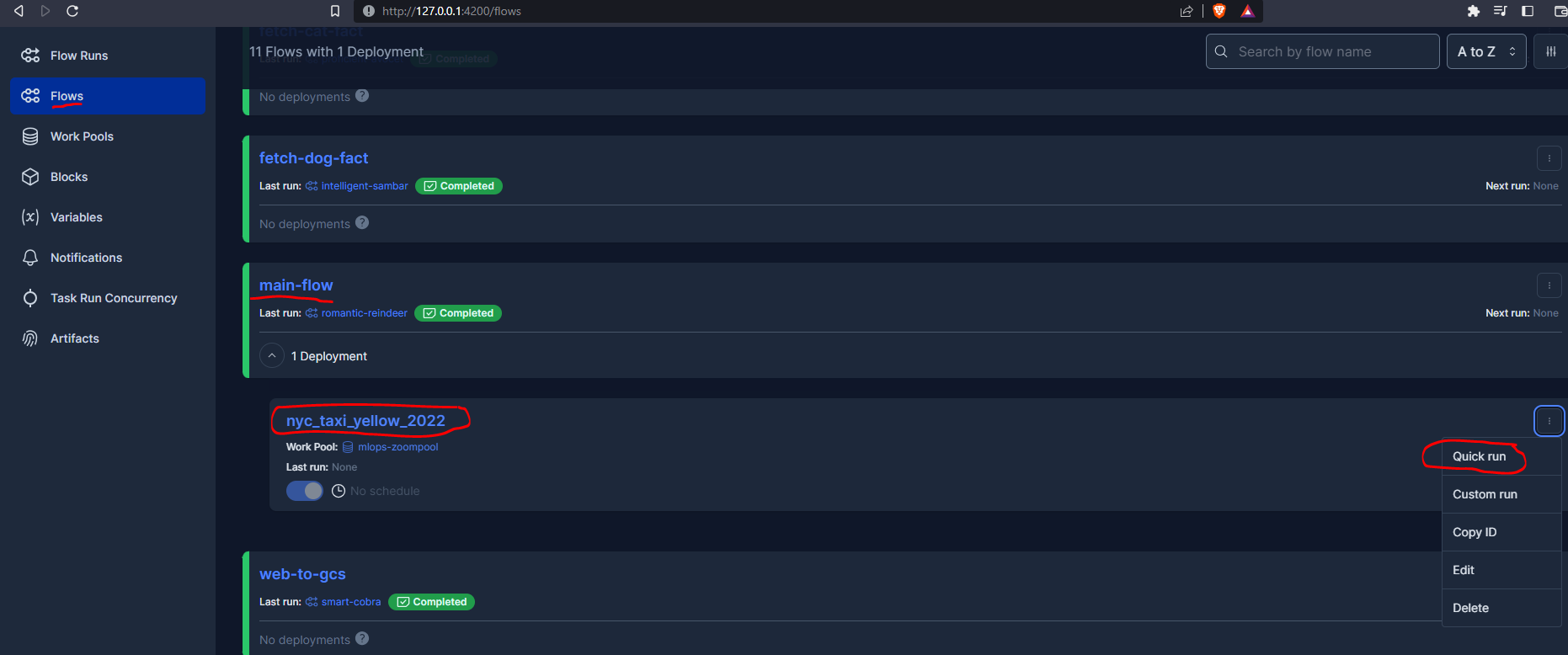
Or from the command line using the template :
prefect deployment <flow_name>/<deploy_name>In my particular case :
prefect deployment run main_flow/nyc_taxi_yellow_2022 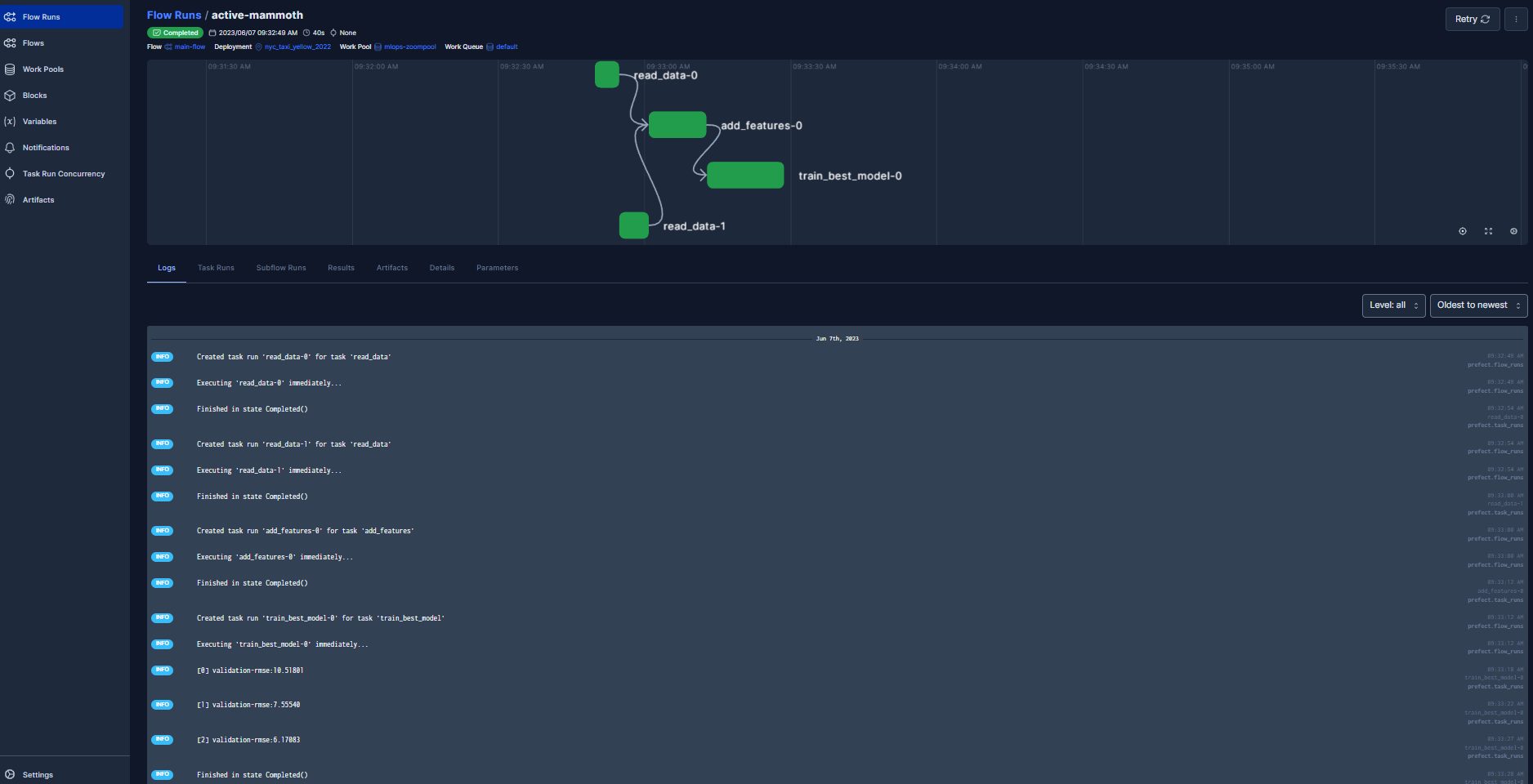
The deployment has been successful. This allows us to collaborate and have something that we can schedule.
3.5 Working with Deployments
In this section we will continue with productionization of our deployments. Although the course covered grabbing data from S3, I was familiar with both Prefect and GCP (which offers a generous $300 90 day free trial) from the Data Engineering Zoomcamp and thought I would have a go at using GCP instead of S3 as my data lake. I set up a new GCP account, configured the Prefect blocks, and modified the orchestration script accordingly.
We will also look at creating multiple deployments from a single project, and add some schedules so we can run our flows in an automated manner.
3.5.1 Grabbing data from GCP
It’s very easy to create Prefect blocks from the UI. If you are feeling adventurous you can also create blocks using a script. You can refer to the guidance documentation for assistance or the GitHub repo.
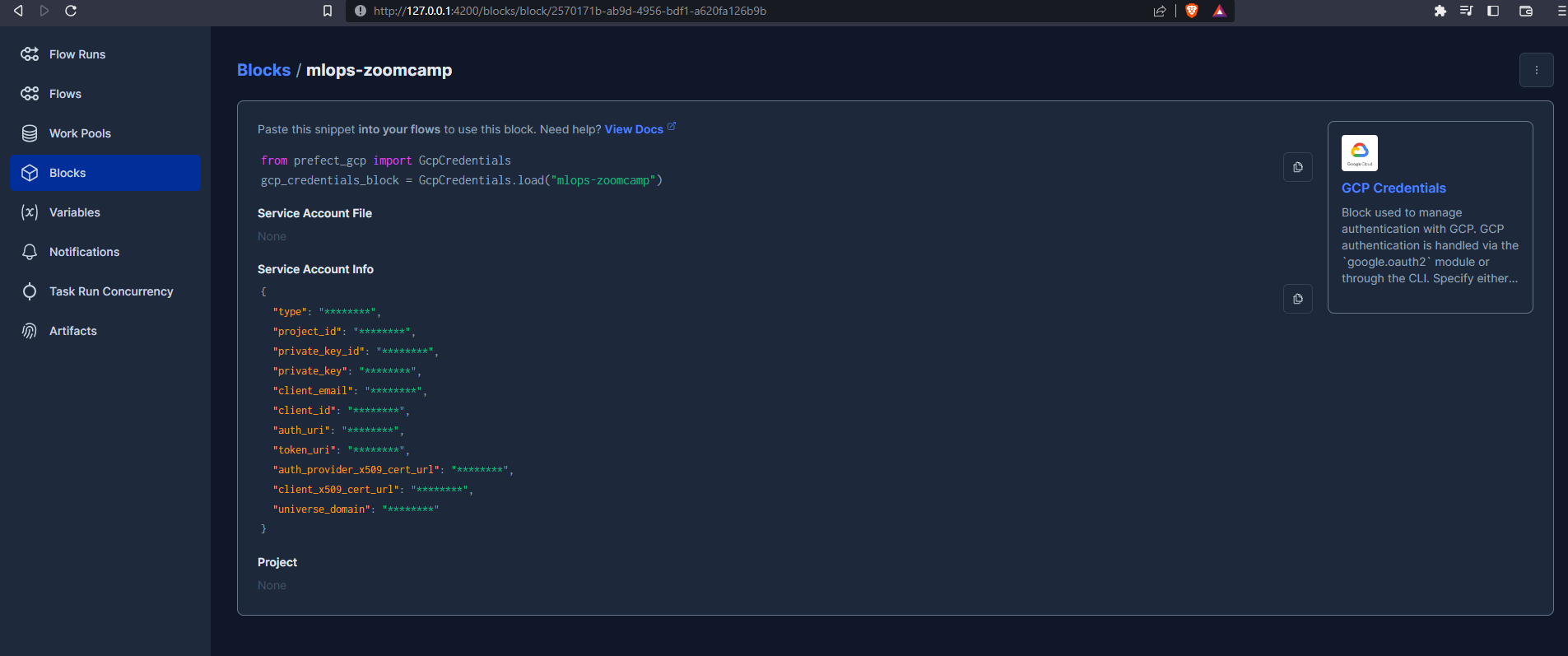
You need to create a Credentials Block, which you give a name and populate with the JSON file downloaded as part of the GCP config :
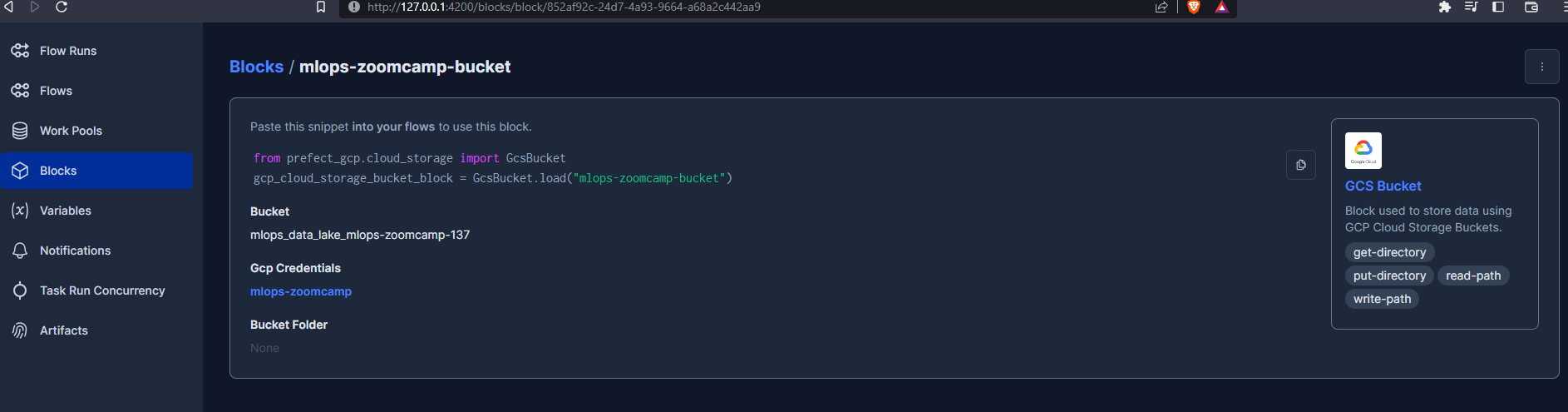
Then create a Bucket block, which references the data lake in GCP :
I then modified the orchestration script to replace S3 block code snipppets with GCP snippets :
orchestrate_gcp.py
import pathlib
import pickle
import pandas as pd
import numpy as np
import scipy
import sklearn
from sklearn.feature_extraction import DictVectorizer
from sklearn.metrics import mean_squared_error
import mlflow
import xgboost as xgb
from prefect import flow, task
from prefect_gcp.cloud_storage import GcsBucket # GCP code snippet to replace the S3 snippet
from prefect.artifacts import create_markdown_artifact
from datetime import date
@task(retries=3, retry_delay_seconds=2)
def read_data(filename: str) -> pd.DataFrame:
"""Read data into DataFrame"""
df = pd.read_parquet(filename)
df.tpep_dropoff_datetime = pd.to_datetime(df.tpep_dropoff_datetime)
df.tpep_pickup_datetime = pd.to_datetime(df.tpep_pickup_datetime)
df["duration"] = df.tpep_dropoff_datetime - df.tpep_pickup_datetime
df.duration = df.duration.apply(lambda td: td.total_seconds() / 60)
df = df[(df.duration >= 1) & (df.duration <= 60)]
categorical = ["PULocationID", "DOLocationID"]
df[categorical] = df[categorical].astype(str)
return df
@task
def add_features(
df_train: pd.DataFrame, df_val: pd.DataFrame
) -> tuple(
[
scipy.sparse._csr.csr_matrix,
scipy.sparse._csr.csr_matrix,
np.ndarray,
np.ndarray,
sklearn.feature_extraction.DictVectorizer,
]
):
"""Add features to the model"""
df_train["PU_DO"] = df_train["PULocationID"] + "_" + df_train["DOLocationID"]
df_val["PU_DO"] = df_val["PULocationID"] + "_" + df_val["DOLocationID"]
categorical = ["PU_DO"] #'PULocationID', 'DOLocationID']
numerical = ["trip_distance"]
dv = DictVectorizer()
train_dicts = df_train[categorical + numerical].to_dict(orient="records")
X_train = dv.fit_transform(train_dicts)
val_dicts = df_val[categorical + numerical].to_dict(orient="records")
X_val = dv.transform(val_dicts)
y_train = df_train["duration"].values
y_val = df_val["duration"].values
return X_train, X_val, y_train, y_val, dv
@task(log_prints=True)
def train_best_model(
X_train: scipy.sparse._csr.csr_matrix,
X_val: scipy.sparse._csr.csr_matrix,
y_train: np.ndarray,
y_val: np.ndarray,
dv: sklearn.feature_extraction.DictVectorizer,
) -> None:
"""train a model with best hyperparams and write everything out"""
with mlflow.start_run():
train = xgb.DMatrix(X_train, label=y_train)
valid = xgb.DMatrix(X_val, label=y_val)
best_params = {
'learning_rate': 0.4434065752589766,
'max_depth': 81,
'min_child_weight': 10.423237853746643,
'objective': 'reg:linear',
'reg_alpha': 0.2630756846813668,
'reg_lambda': 0.1220536223877784,
'seed': 42
}
mlflow.log_params(best_params)
booster = xgb.train(
params=best_params,
dtrain=train,
num_boost_round=3,
evals=[(valid, "validation")],
early_stopping_rounds=3,
)
y_pred = booster.predict(valid)
rmse = mean_squared_error(y_val, y_pred, squared=False)
mlflow.log_metric("rmse", rmse)
pathlib.Path("models").mkdir(exist_ok=True)
with open("models/preprocessor.b", "wb") as f_out:
pickle.dump(dv, f_out)
mlflow.log_artifact("models/preprocessor.b", artifact_path="preprocessor") # create an artifact which we can visualize in the UI
mlflow.xgboost.log_model(booster, artifact_path="models_mlflow")
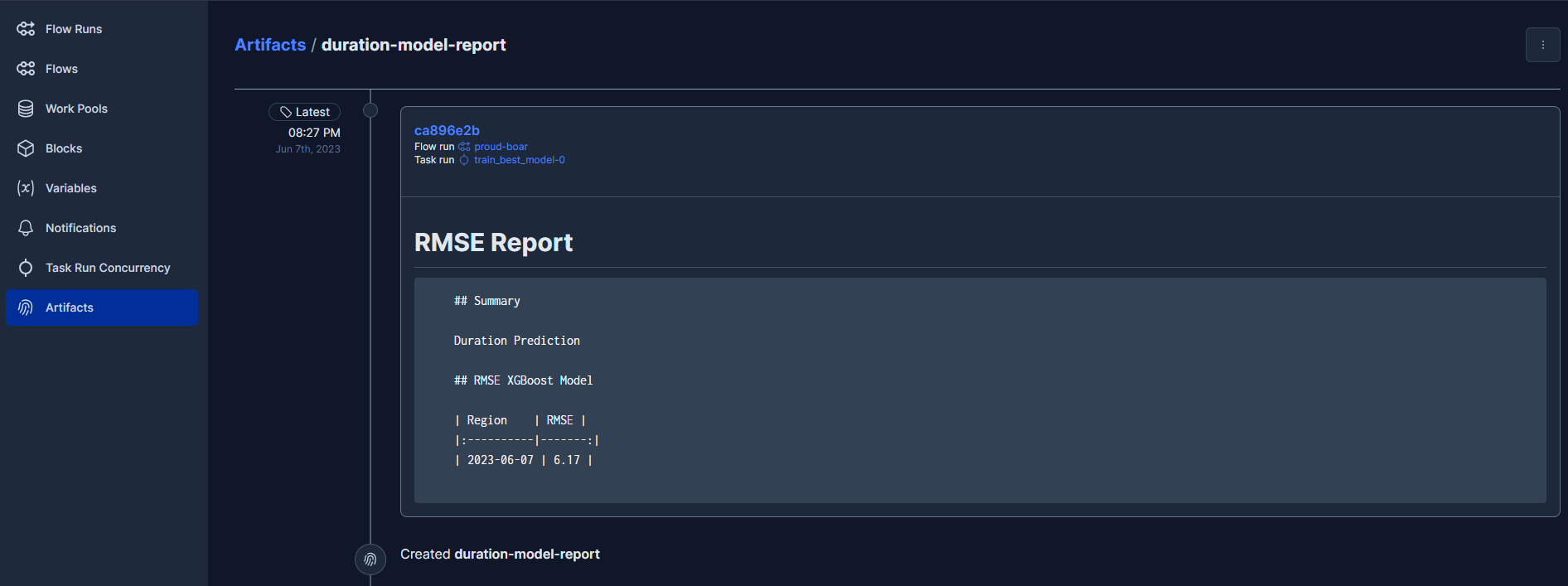
markdown__rmse_report = f"""# RMSE Report
## Summary
Duration Prediction
## RMSE XGBoost Model
| Region | RMSE |
|:----------|-------:|
| {date.today()} | {rmse:.2f} |
"""
create_markdown_artifact(
key="duration-model-report", markdown=markdown__rmse_report
)
return None
@flow
def main_flow_gcp(
train_path: str = "data/yellow_tripdata_2022-01.parquet",
val_path: str = "data/yellow_tripdata_2022-02.parquet",
) -> None:
"""The main training pipeline"""
# MLflow settings
mlflow.set_tracking_uri("sqlite:///mlflow.db")
mlflow.set_experiment("nyc-taxi-experiment")
# Load
gcp_cloud_storage_bucket_block = GcsBucket.load("mlops-zoomcamp-bucket") # GCP code snippet to replace the S3 snippet
gcp_cloud_storage_bucket_block.download_folder_to_path(from_folder="data", to_folder="data") # GCP code snippet to replace the S3 snippet
df_train = read_data(train_path)
df_val = read_data(val_path)
# Transform
X_train, X_val, y_train, y_val, dv = add_features(df_train, df_val)
# Train
train_best_model(X_train, X_val, y_train, y_val, dv)
if __name__ == "__main__":
main_flow_gcp()And then ran the script from the command line using :
python orchestrate_gcp.py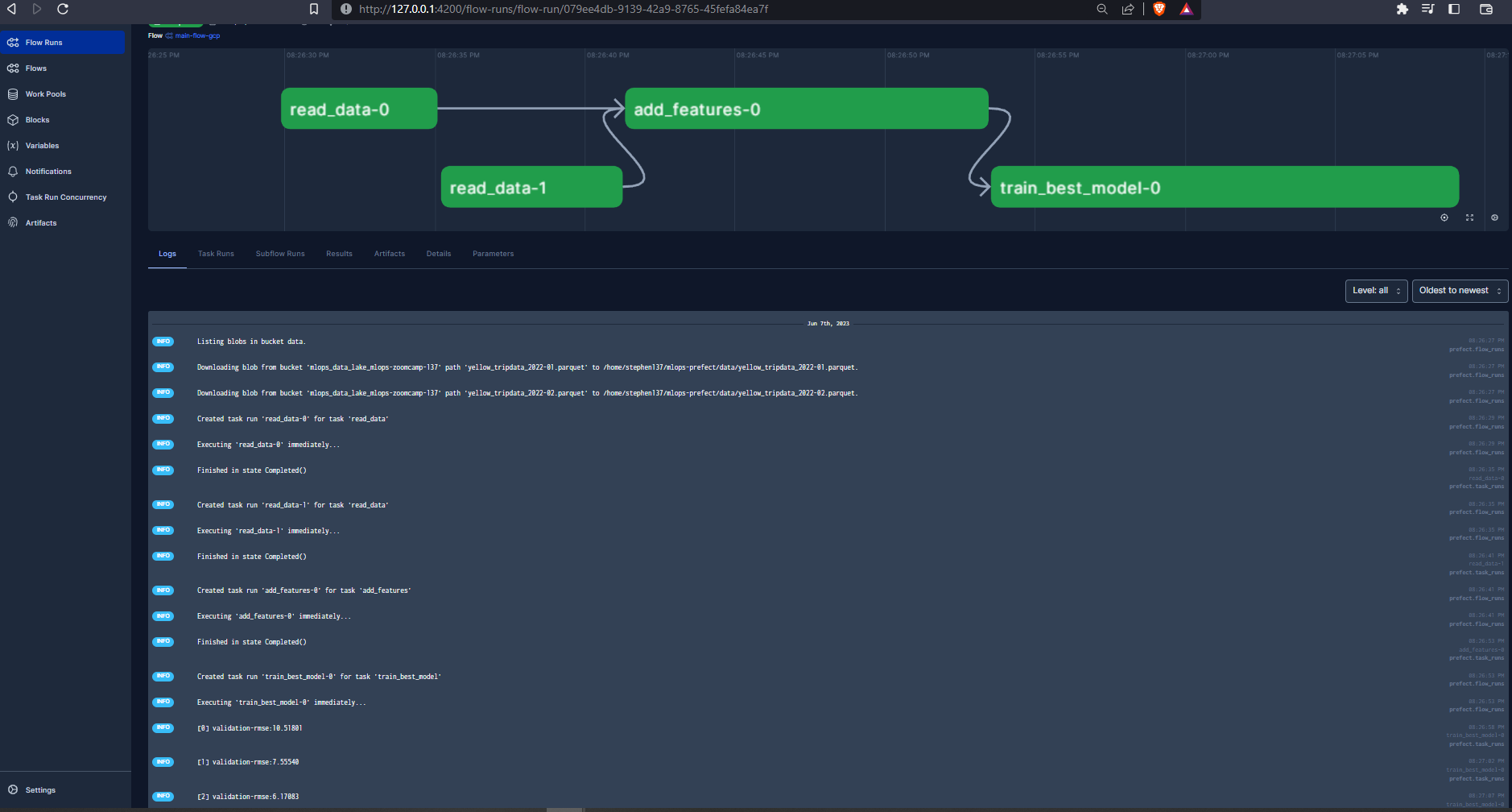
The run completed successfully and we can see the artifact that we tagged in our script which logs the best RMSE in the UI :
3.5.2 Multiple deployments from the one project
To do this we need to re-configure
deployment.yaml
deployments:
- name: nyc_taxi_yellow_2022
entrypoint: orchestrate.py:main_flow
work_pool:
name: mlops-zoompool
- name: nyc_taxi_yellow_2022_gcp
entrypoint: orchestrate_gcp.py:main_flow_gcp
work_pool:
name: mlops-zoompoolWe can deploy both of the above from the command line :
prefect deploy --allAnd then starting a worker :
prefect worker start -p mlops-zoompool
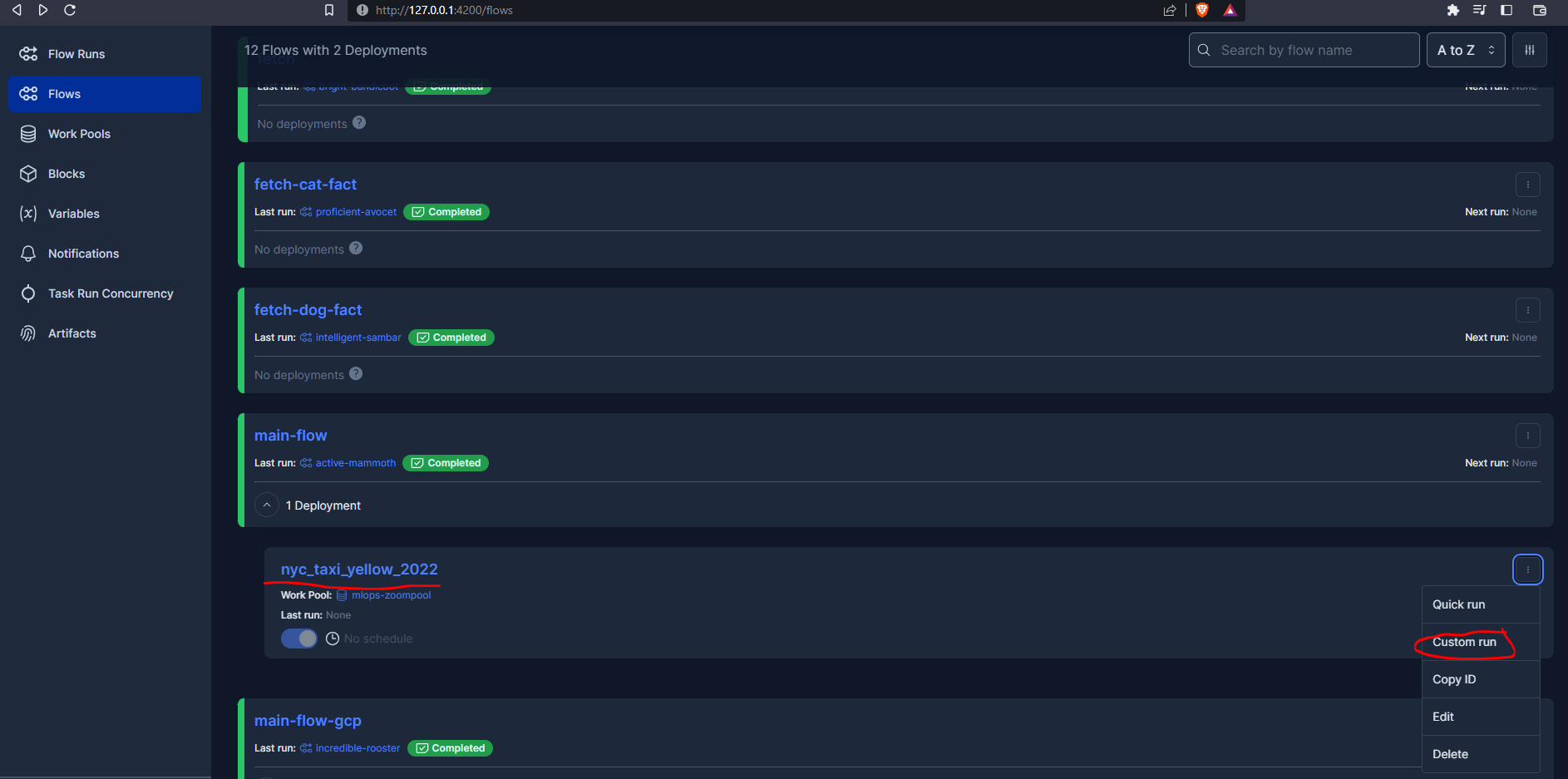
3.5.3 Customized runs (scheduling)
We can customize our run from the UI :
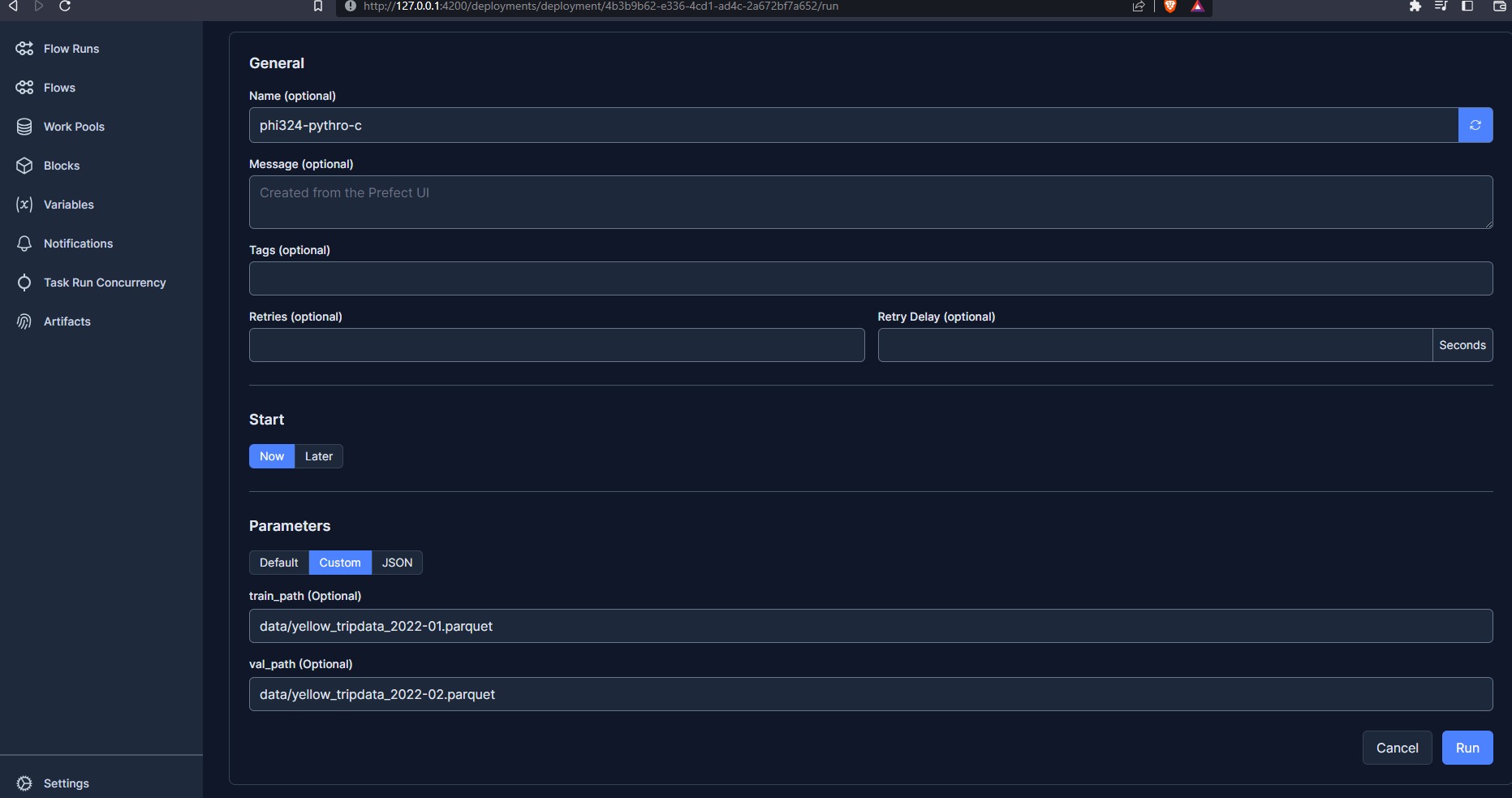
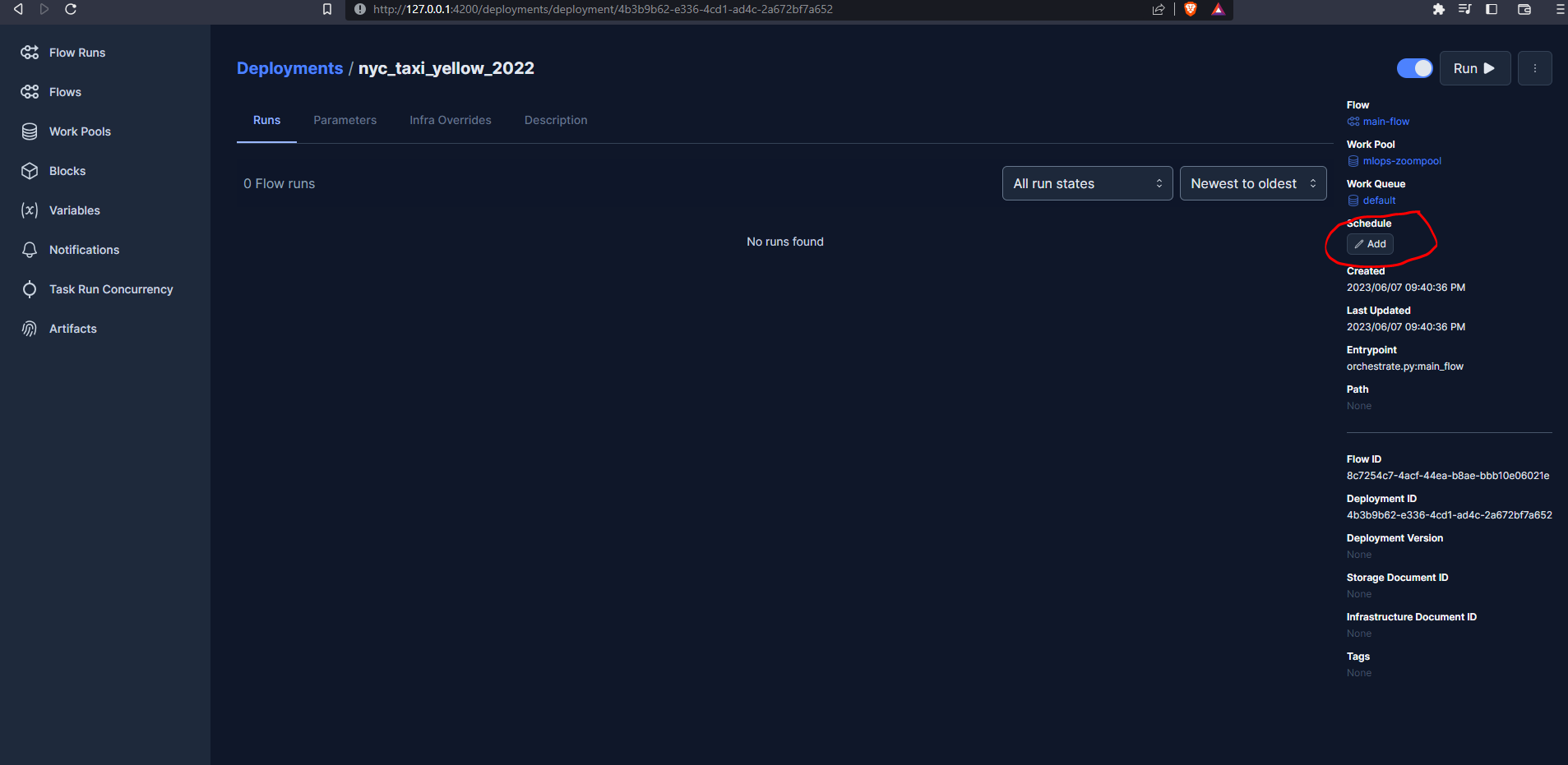
We can also schedule runs from the UI :
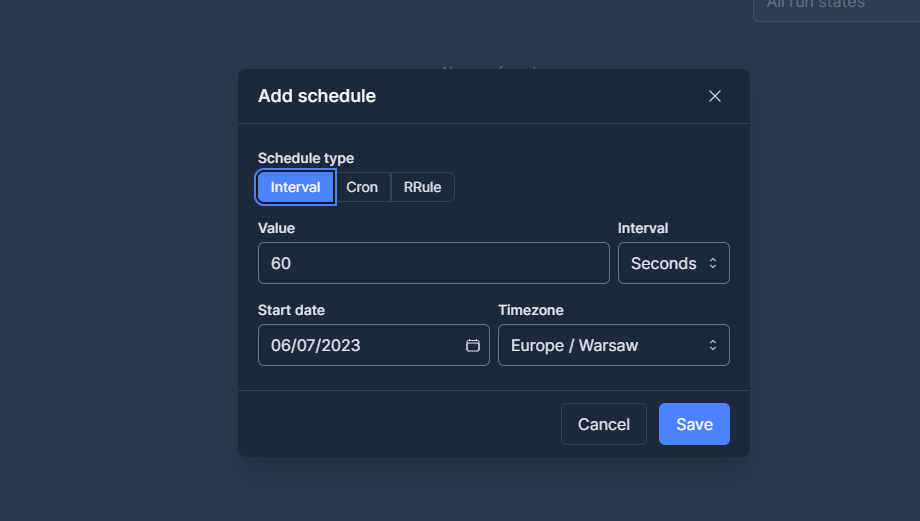
It is also possible to schedule runs from the command line, for example :
prefect deployment set-schedule main_flow/taxi --interval 120 # default is secondsWe’ve covered a lot in this section. We’ve seen how to schedule deployments, add artifacts, load data from GCP using blocks, and how to change the parameters of our runs using both the UI and the command line.
3.6 Prefect Cloud
First, navigate to Prefect Cloud and sign in.
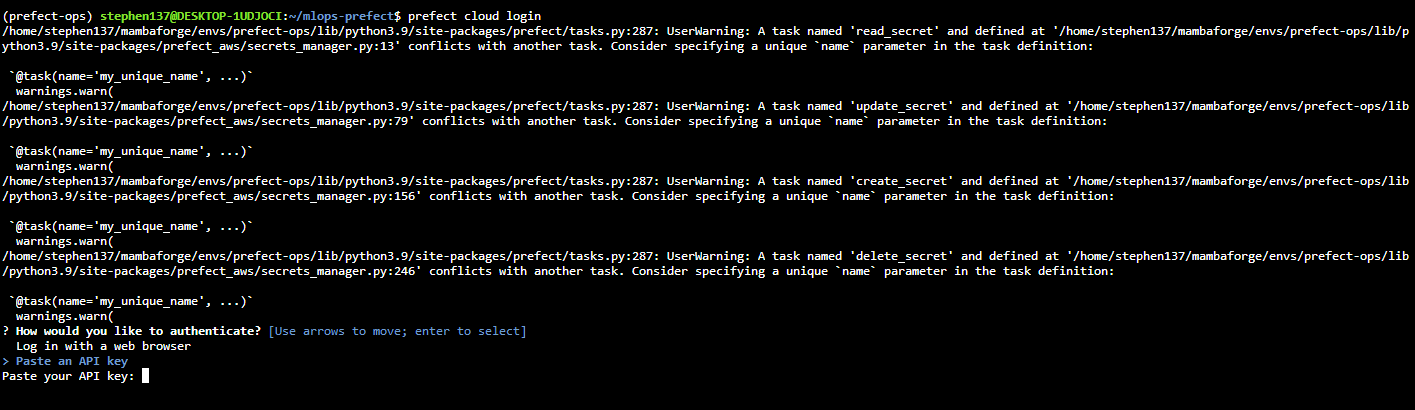
Then to get up and running from the command line :
prefect cloud loginYou need to authenticate, either by log in with a web browser (which didn’t work for me) or by an API key which you can create from the Ui :
The next step is to register and configure any necessary Blocks as described in the previous section, and then we can start a worker as before :
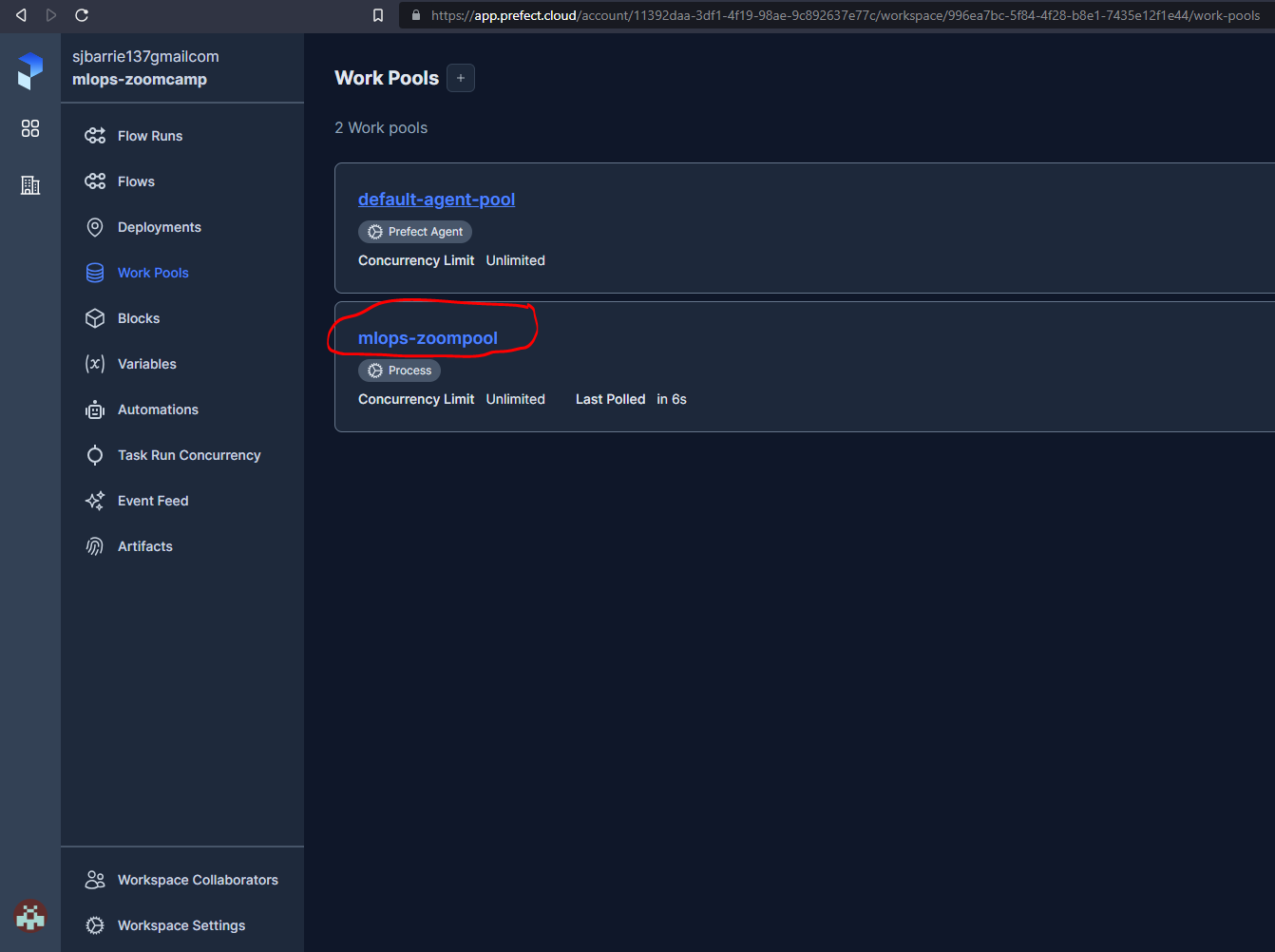
3.6.1 Automations
A useful feature within Prefect is Automations which allows us to configure a variety of customizable notifications. For example, here we will see how to set up an email notification, from the cloud UI. First we need to add the required blocks :
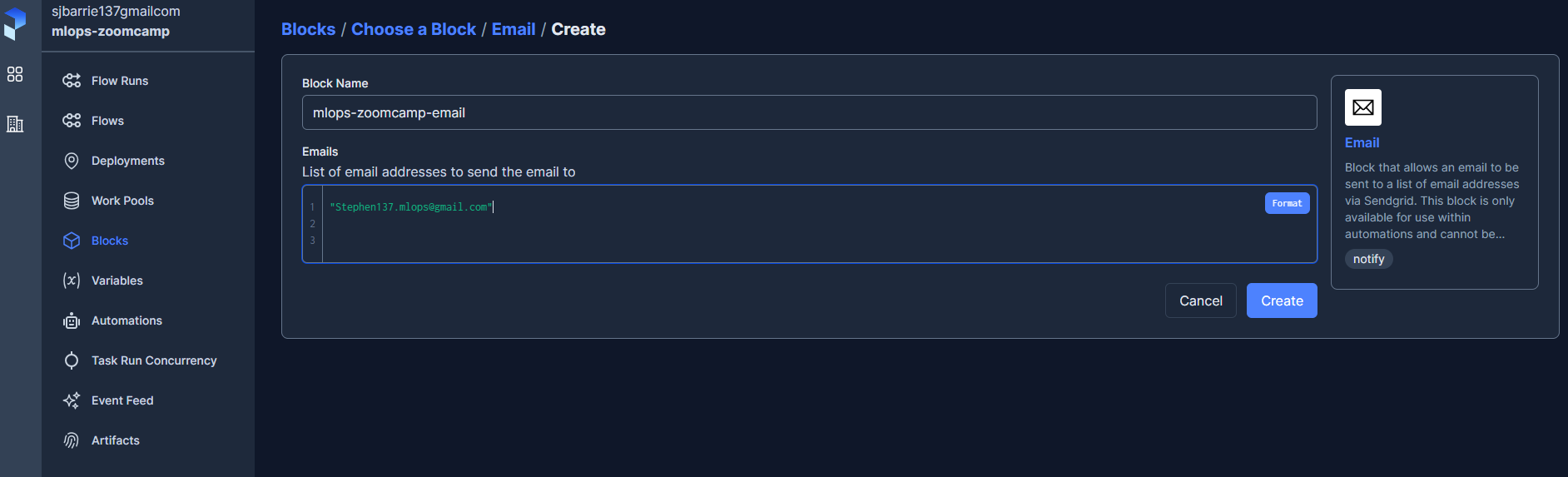
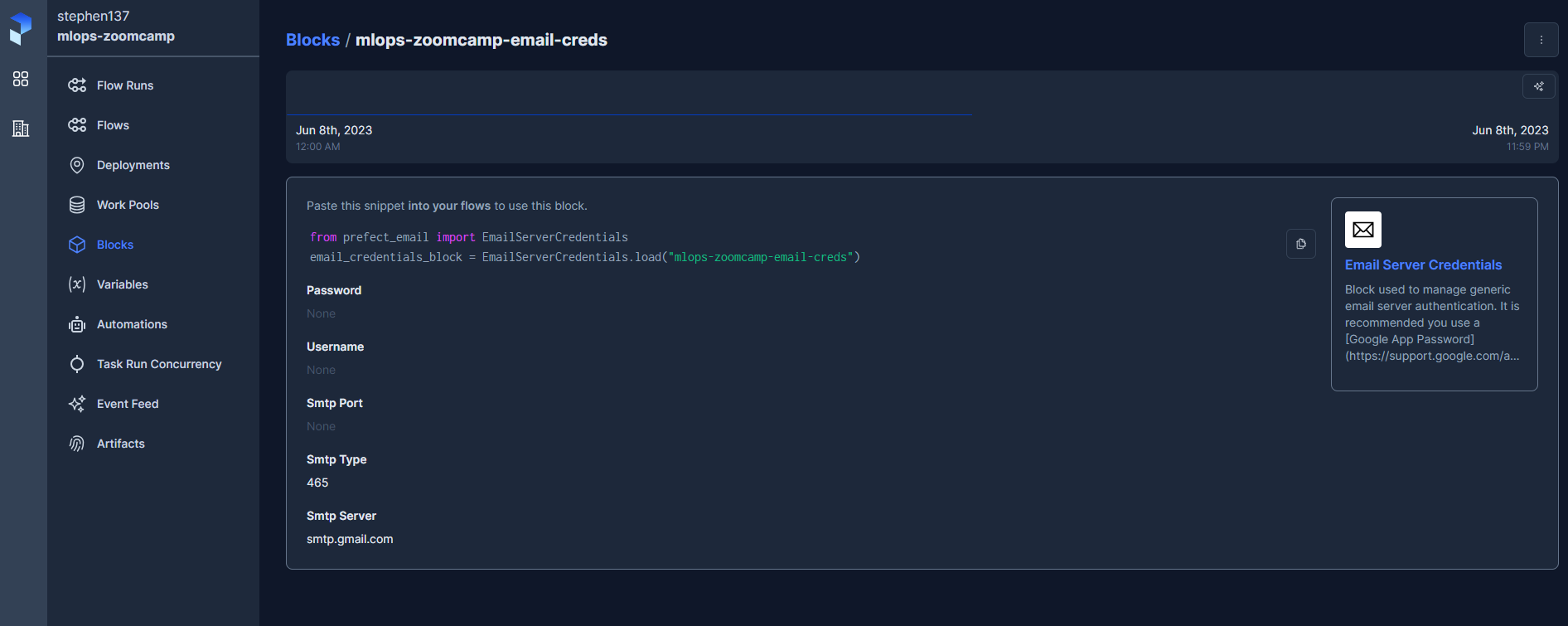
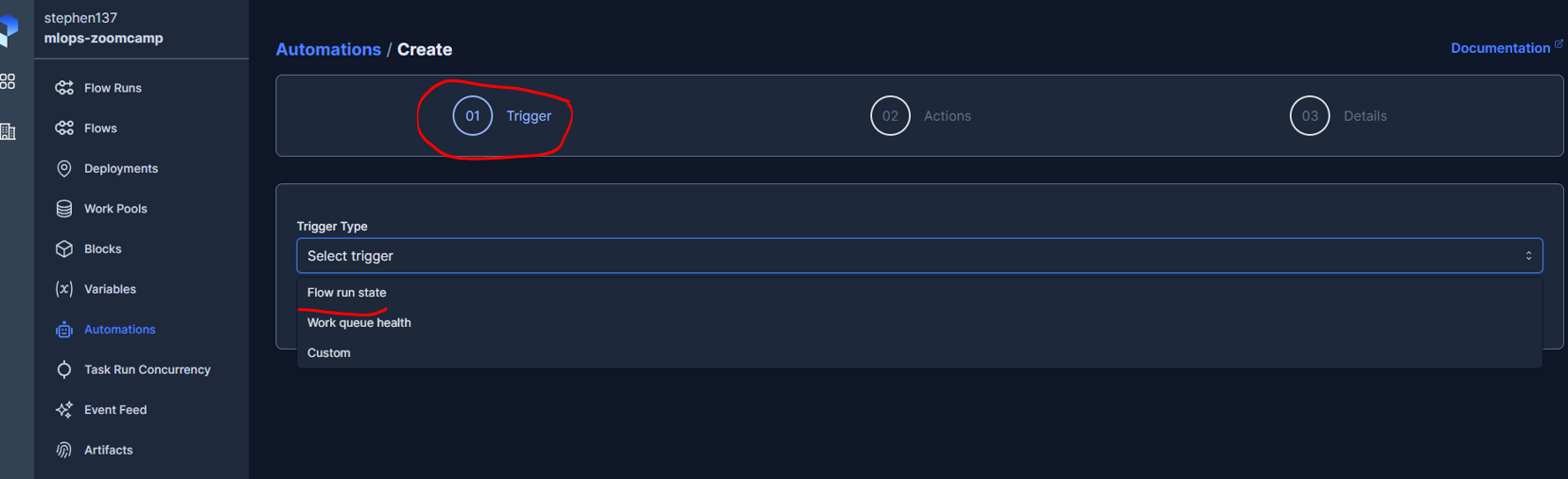
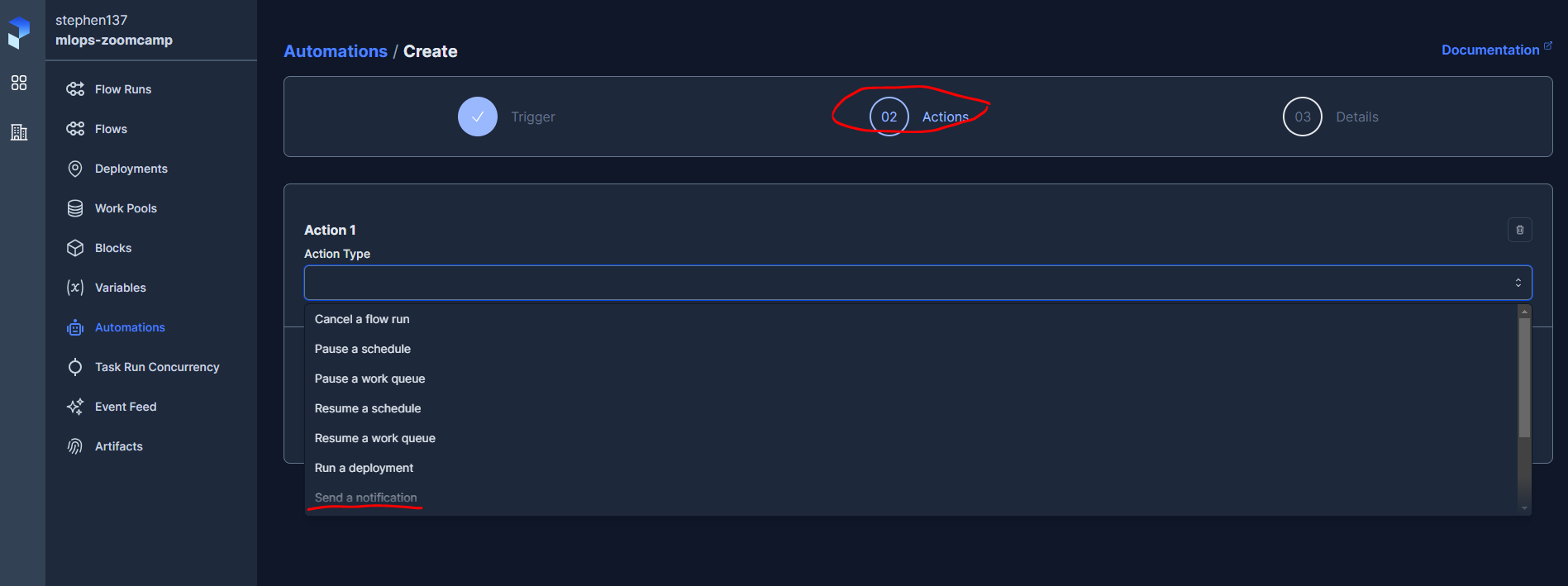
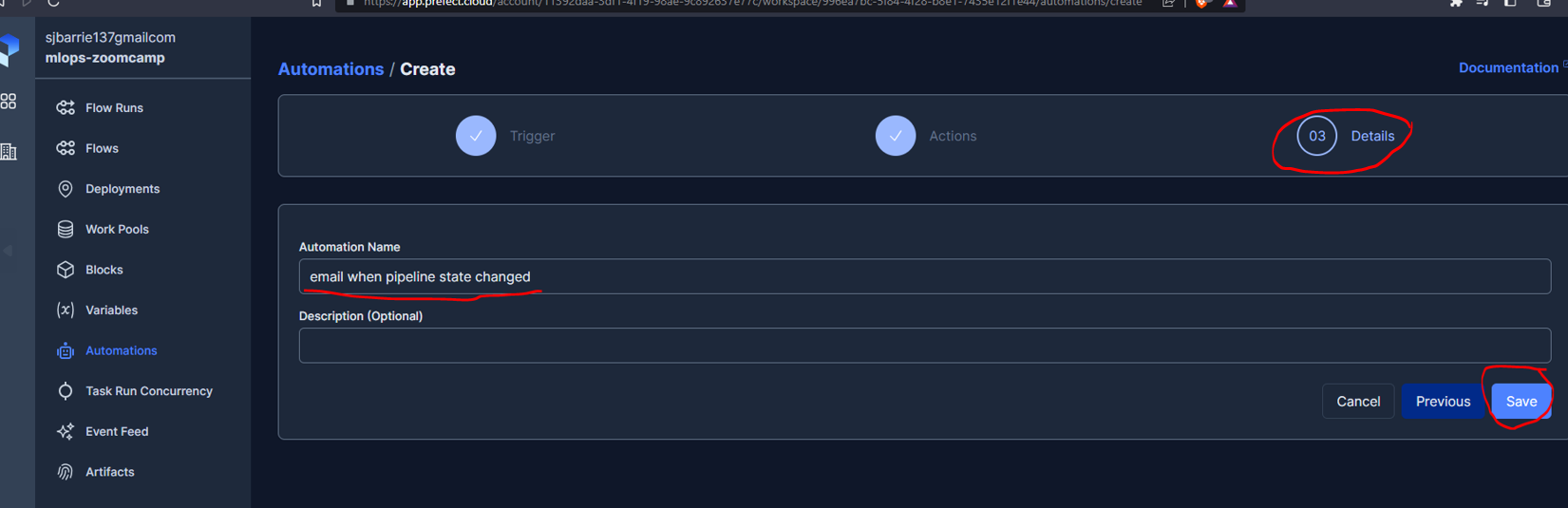
I then deployed the following script :
orchestrate_f_m_23.py
import pathlib
import pickle
import pandas as pd
import numpy as np
import scipy
import sklearn
from sklearn.feature_extraction import DictVectorizer
from sklearn.metrics import mean_squared_error
import mlflow
import xgboost as xgb
from prefect import flow, task
from prefect.artifacts import create_markdown_artifact
from datetime import date
@task(retries=3, retry_delay_seconds=2)
def read_data(filename: str) -> pd.DataFrame:
"""Read data into DataFrame"""
df = pd.read_parquet(filename)
df.lpep_dropoff_datetime = pd.to_datetime(df.lpep_dropoff_datetime)
df.lpep_pickup_datetime = pd.to_datetime(df.lpep_pickup_datetime)
df["duration"] = df.lpep_dropoff_datetime - df.lpep_pickup_datetime
df.duration = df.duration.apply(lambda td: td.total_seconds() / 60)
df = df[(df.duration >= 1) & (df.duration <= 60)]
categorical = ["PULocationID", "DOLocationID"]
df[categorical] = df[categorical].astype(str)
return df
@task
def add_features(
df_train: pd.DataFrame, df_val: pd.DataFrame
) -> tuple(
[
scipy.sparse._csr.csr_matrix,
scipy.sparse._csr.csr_matrix,
np.ndarray,
np.ndarray,
sklearn.feature_extraction.DictVectorizer,
]
):
"""Add features to the model"""
df_train["PU_DO"] = df_train["PULocationID"] + "_" + df_train["DOLocationID"]
df_val["PU_DO"] = df_val["PULocationID"] + "_" + df_val["DOLocationID"]
categorical = ["PU_DO"] #'PULocationID', 'DOLocationID']
numerical = ["trip_distance"]
dv = DictVectorizer()
train_dicts = df_train[categorical + numerical].to_dict(orient="records")
X_train = dv.fit_transform(train_dicts)
val_dicts = df_val[categorical + numerical].to_dict(orient="records")
X_val = dv.transform(val_dicts)
y_train = df_train["duration"].values
y_val = df_val["duration"].values
return X_train, X_val, y_train, y_val, dv
@task(log_prints=True)
def train_best_model(
X_train: scipy.sparse._csr.csr_matrix,
X_val: scipy.sparse._csr.csr_matrix,
y_train: np.ndarray,
y_val: np.ndarray,
dv: sklearn.feature_extraction.DictVectorizer,
) -> None:
"""train a model with best hyperparams and write everything out"""
with mlflow.start_run():
train = xgb.DMatrix(X_train, label=y_train)
valid = xgb.DMatrix(X_val, label=y_val)
best_params = {
"learning_rate": 0.09585355369315604,
"max_depth": 30,
"min_child_weight": 1.060597050922164,
"objective": "reg:linear",
"reg_alpha": 0.018060244040060163,
"reg_lambda": 0.011658731377413597,
"seed": 42,
}
mlflow.log_params(best_params)
booster = xgb.train(
params=best_params,
dtrain=train,
num_boost_round=100,
evals=[(valid, "validation")],
early_stopping_rounds=20,
)
y_pred = booster.predict(valid)
rmse = mean_squared_error(y_val, y_pred, squared=False)
mlflow.log_metric("rmse", rmse)
pathlib.Path("models").mkdir(exist_ok=True)
with open("models/preprocessor.b", "wb") as f_out:
pickle.dump(dv, f_out)
mlflow.log_artifact("models/preprocessor.b", artifact_path="preprocessor")
mlflow.xgboost.log_model(booster, artifact_path="models_mlflow")
markdown__rmse_report = f"""# RMSE Report
## Summary
Duration Prediction
## RMSE XGBoost Model
| Region | RMSE |
|:----------|-------:|
| {date.today()} | {rmse:.2f} |
"""
create_markdown_artifact(
key="duration-model-report", markdown=markdown__rmse_report
)
return None
@flow
def main_flow_f_m_23(
train_path: str = "./data/green_tripdata_2023-02.parquet",
val_path: str = "./data/green_tripdata_2023-03.parquet",
) -> None:
"""The main training pipeline"""
# MLflow settings
mlflow.set_tracking_uri("sqlite:///mlflow.db")
mlflow.set_experiment("nyc-taxi-experiment")
# Load
df_train = read_data(train_path)
df_val = read_data(val_path)
# Transform
X_train, X_val, y_train, y_val, dv = add_features(df_train, df_val)
# Train
train_best_model(X_train, X_val, y_train, y_val, dv)
if __name__ == "__main__":
main_flow_f_m_23()from the command line using :
prefect deploy orchestrate_f_m_23.py:main_flow_f_m_23 -n nyc_taxi_green_f_m_23 -p mlops-zoompool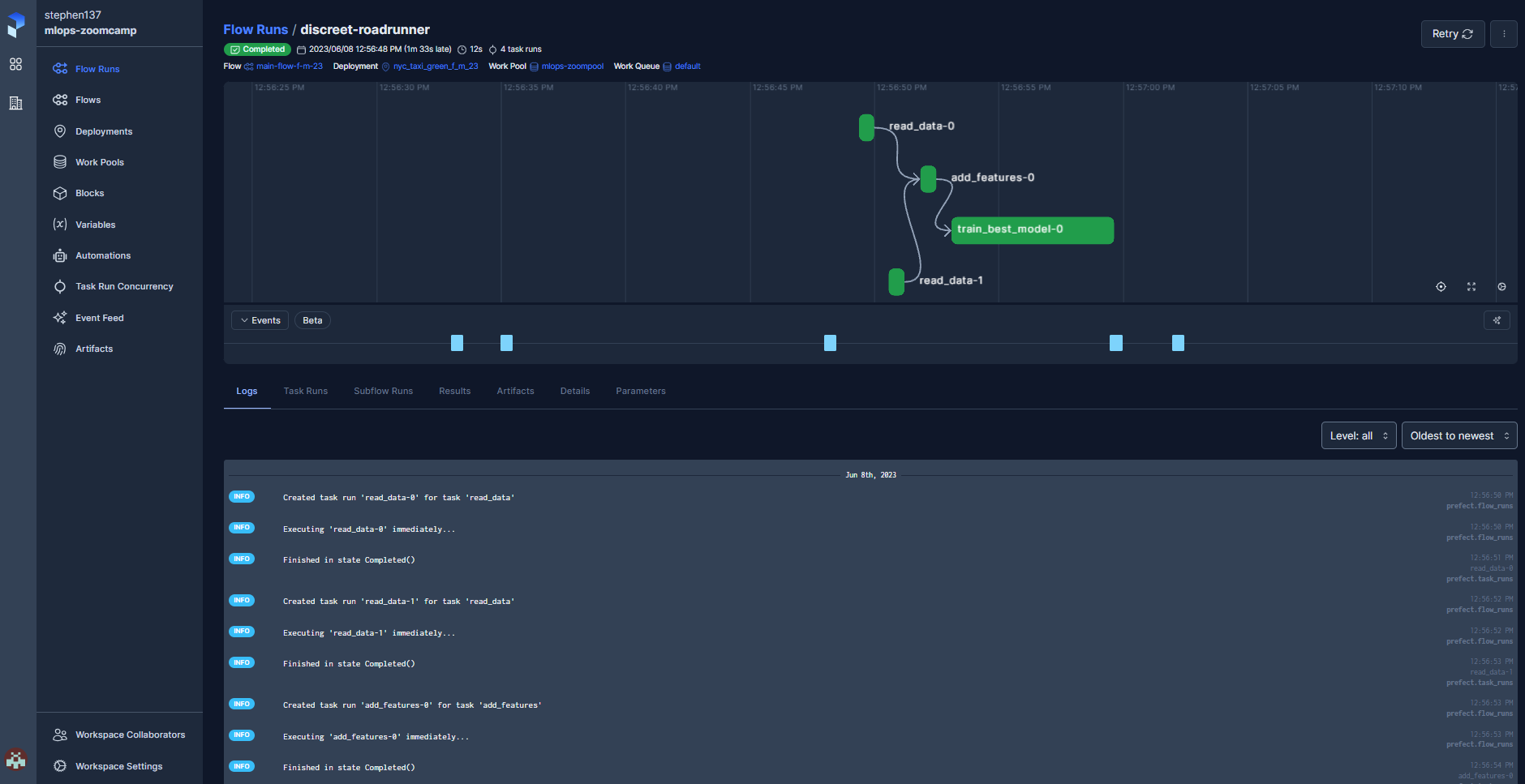
When the run was succesfully completed I received the following email notification :
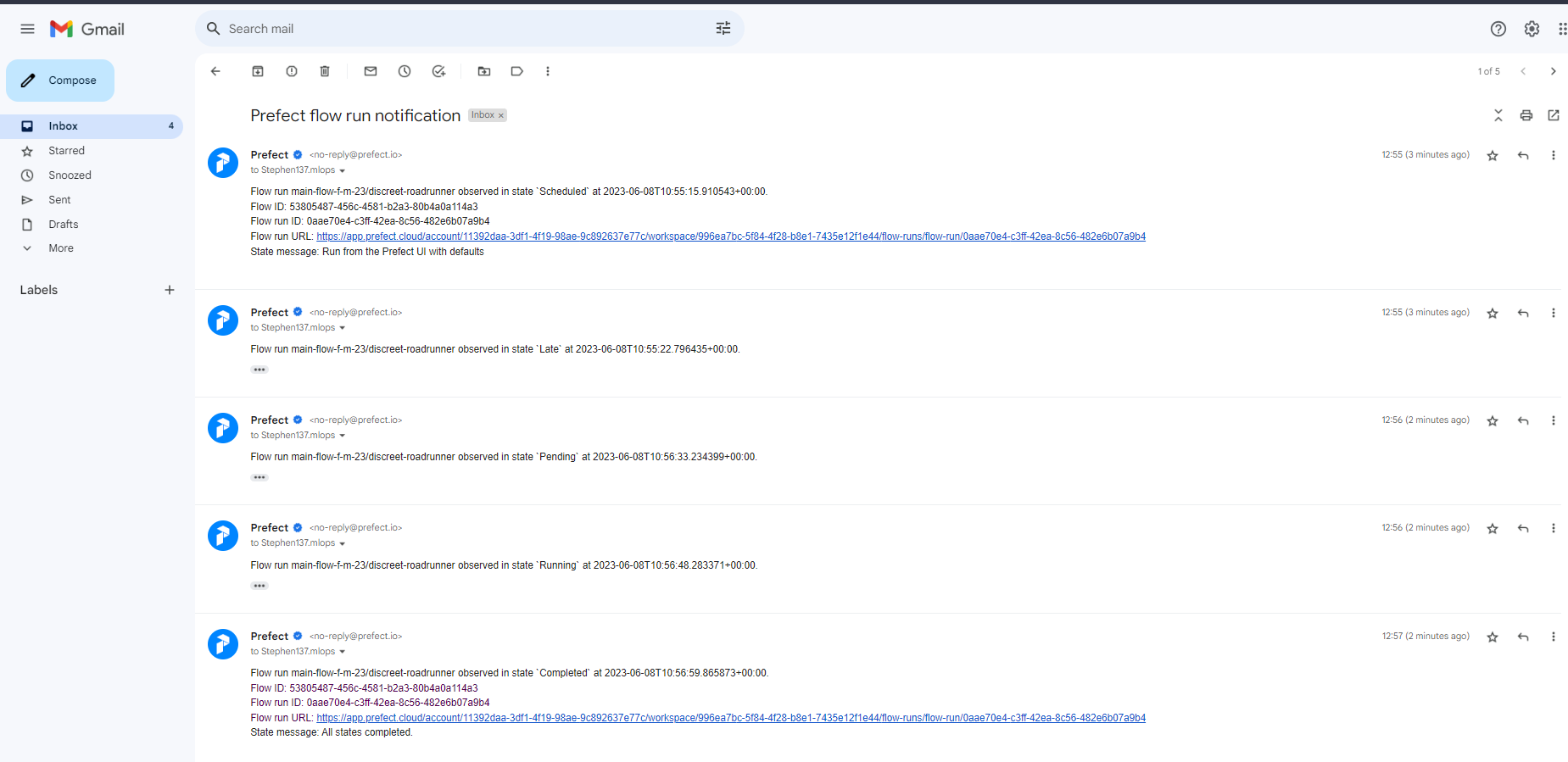
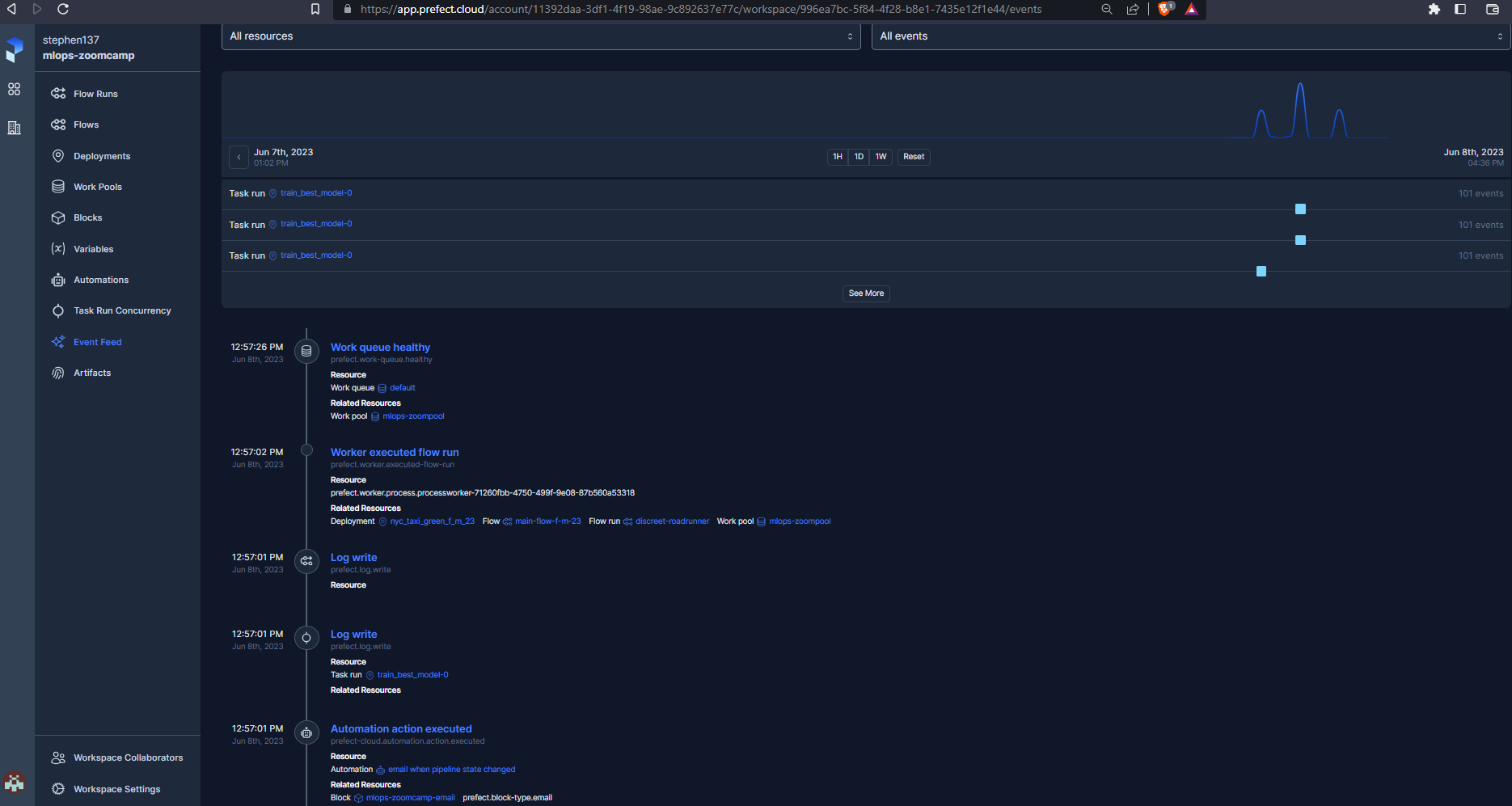
We can see a timeline summary of events in the Event Feed :